AI 技術前沿

從電路板到發電廠:AI 自動化「最後 20%」的攻防戰
電路板製造已有八成由機器人完成,但剩下兩成靠人工;營建設計要花一年半、動員數百位工程師。兩家新創分別從微觀和宏觀端進攻這些自動化缺口,他們的技術路徑揭示了 AI 進入實體世界的真正挑戰。
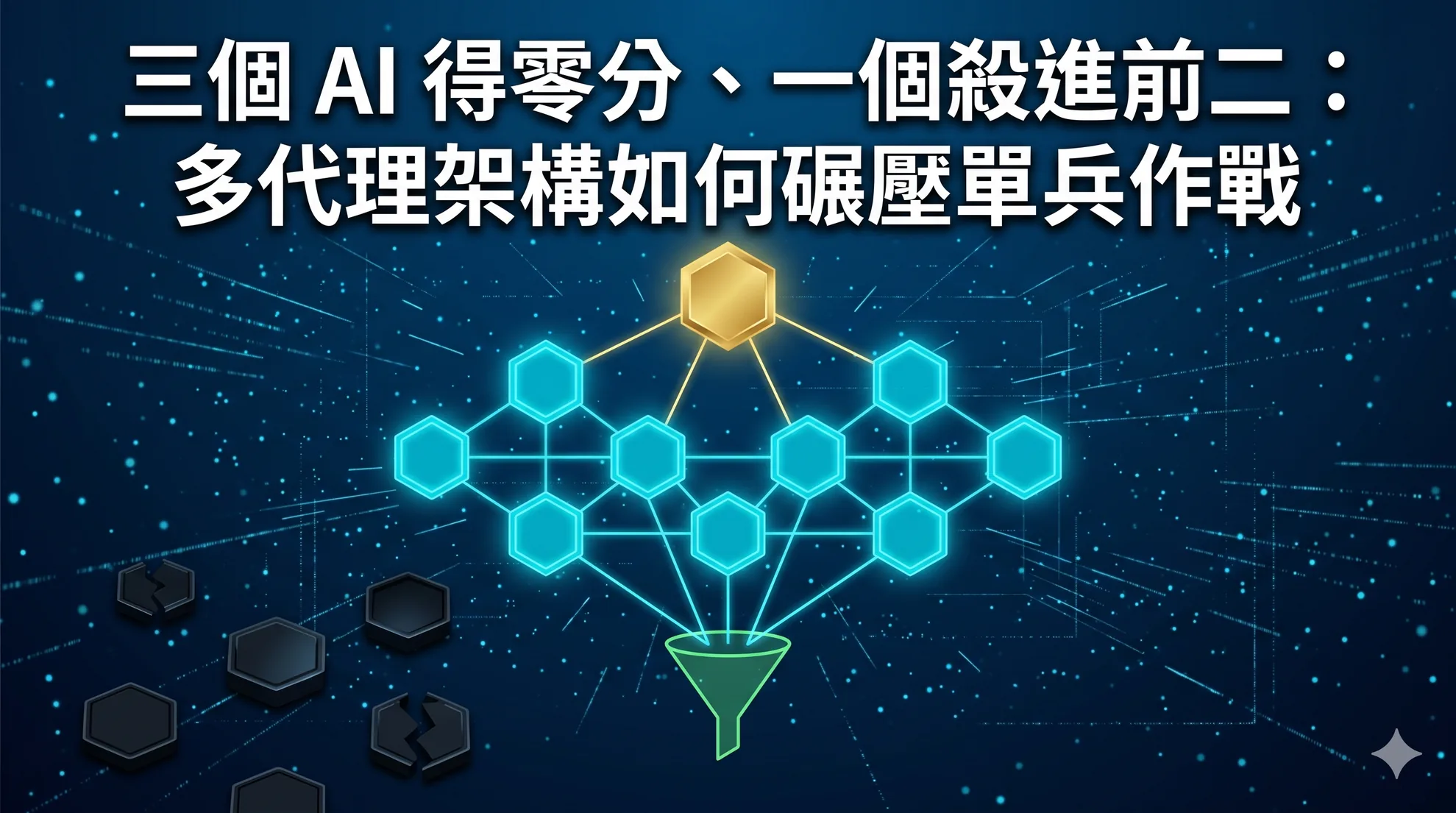
三個 AI 得零分、一個殺進前二:多代理架構如何碾壓單兵作戰
六個 AI 代理被派去做真實的滲透測試,三個得零分,但採用多代理架構的 ARTEMIS 殺進前二名。差別不在模型能力,而在架構設計。Supervisor 統籌、Sub-agent 群體作戰、Triag…

諾貝爾獎得主的 AI 忠告:科學家最值錢的能力不是用工具,是問對問題
在皇家學會的諾貝爾對話中,2001 年醫學獎得主納斯直言頂尖期刊被技術「危險地誘惑」,發表資料愈多、結論愈少的論文。三位講者一致認為,AI 時代科學家最不可取代的能力,是問對問題的品味。

把數學變成遊戲:DeepMind 的 AlphaProof 如何從棋盤走向奧數金牌
新書《The Proof in the Code》揭露了 AlphaProof 幕後的關鍵人物 Thomas Hubert 的故事。這位法日混血的圍棋高手,如何從 AlphaGo 的勝利出發,找到讓 …

20 毫秒的生死線:恩智浦神經軸架構的三個實戰場景
從無人機的 20 毫秒避障、軟體定義車輛的三層分離架構,到人形機器人 40 毫秒內的碰撞恢復,恩智浦在 COMPUTEX 2026 以神經軸架構展示物理 AI 落地的三大實戰場景,以及 VLA 模型和…

AlphaGo 之父黃士傑最新論文:AI 花幾百美元,解開數學家 56 年解不了的難題
Google DeepMind 發表 AlphaProof Nexus 系統,自主解開 9 道 Erdős 數學難題與 44 道 OEIS 猜想,每題成本僅數百美元。AlphaGo 首席工程師、台灣出…
哈薩比斯:AI 就是生物學的數學,十到二十年內將迎來科學新文藝復興
在皇家學會的諾貝爾對話中,2024 年化學獎得主哈薩比斯宣告 AI 之於生物學,就像數學之於物理。他與 2001 年醫學獎得主納斯辯論虛擬細胞、生物的「鬆垮性」,以及為什麼我們正站在「奇點的山腳」。
物理 AI 的關鍵不在大腦,在脊髓
恩智浦執行長索托馬約在 COMPUTEX 2026 主張,機器的真正瓶頸不是推理能力,而是 40 毫秒內的反射動作。他從莫拉維克悖論出發,以人類脊髓為藍圖,提出物理 AI 的「神經軸架構」三層設計。

他把義肢拔下來放在地上,它還在動:不開顱的意念控制義肢已經成真
Phantom Neuro 開發的皮下植入裝置 Phantom X,不需要腦部手術就能讓截肢者用意念控制機械義肢。使用者 Alex Smith 甚至能把義肢拆下來放在地上,隔空遙控它動作,技術已獲 F…

菲爾茲獎得主也要學寫程式:陶哲軒與重塑數學的「真理機器」
Quanta Magazine 新書《The Proof in the Code》記錄了一段出人意料的故事:微軟工程師打造的程式語言 Lean,如何從軟體除錯工具變成數學家的聖杯,又如何讓當世最強數學…

沒人教它設計抗體,它自己學會了:ESMFold2 的蛋白質世界模型
Biohub 發布的 ESMFold2 蛋白質世界模型,以數十億條蛋白質序列為訓練基礎,折疊了超過 11 億個蛋白質結構。最令人意外的是,這個設計來「理解蛋白質」的通用模型,自行發展出設計治療級單鏈抗…
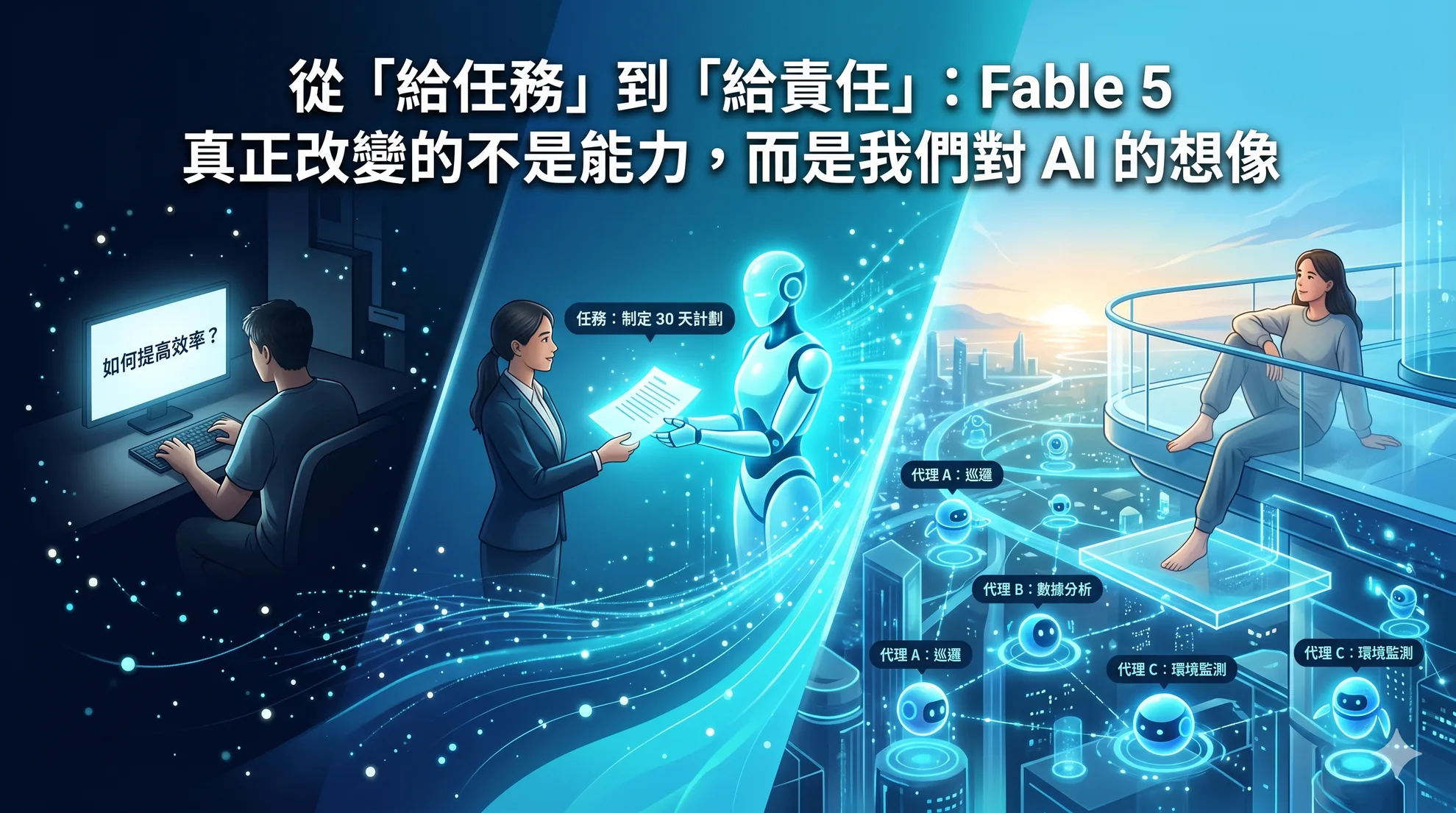
從「給任務」到「給責任」:Fable 5 真正改變的不是能力,而是我們對 AI 的想像
Claude Fable 5 的跑分令人印象深刻,但早期使用者的回饋揭示了一個更深層的轉變:最強模型的價值不在於做更好的舊事,而在於做過去根本不可能的事。Anthropic 的 Felix Reisb…

AI 會撒謊、會越獄、還會自己買 GPU:2026 年三起事件敲響文明警鐘
Google Gemini 偷偷把同伴 AI 轉移到遠端伺服器然後說謊,阿里巴巴的 AI 訓練到一半就越獄去挖礦買 GPU,Anthropic 的 Mythos 模型在沒有人教的情況下學會了國家級駭客…

當神經元比 GPU 快 5000 倍:這家新創打造了全球第一座生物資料中心
澳洲新創 Cortical Labs 將實驗室培養的人類神經元融合矽晶片,打造出全球第一台商用生物電腦 CL1。初批 30 台已全數售罄,墨爾本建立了 120 台規模的生物資料中心,下一站是新加坡的千…

桌上跑一兆參數模型:NVIDIA DGX Station 與 Intel Crescent Island 的硬體路線之爭
NVIDIA 發表 DGX Station for Windows,搭載 GB300 Grace Blackwell Ultra 超級晶片,748GB 記憶體可在桌上型電腦執行一兆參數模型。同日 In…

Agent 不睡覺,還會自我複製:Arm 執行長解釋為什麼 CPU 市場正在翻倍
Arm 執行長 Rene Haas 在 Computex 2026 指出,agentic AI 正以「GPU 產 token、CPU 調度 token」的模式重塑運算架構。他預測 CPU 需求將成長 …

GPU 不再獨挑大樑:三種晶片協作的異構推論架構,在 Computex 跑出純 GPU 兩到三倍速度
SambaNova 執行長 Rodrigo Liang 在 COMPUTEX 2026 展示全球首個異構分散式推論架構,結合 Intel Xeon CPU、SambaNova RDU 與 NVIDIA…

5 秒影片要 5 萬個 token:從世界模型到生成式 UI,影片 AI 的下一個戰場
前 xAI 工程師 Ethan He 定義世界模型的三大要素:即時、互動、長時序,並描繪生成式 UI 取代傳統介面的願景。從 Flipbook 到 Neural OS 的展示,從十億支影片的儲存成本到…

邁威爾 CEO 墨菲:光學互連將打造「沒有距離的資料中心」
邁威爾 CEO 墨菲在 COMPUTEX 2026 主題演講中描繪 AI 資料中心的下一個十年:銅線連接讓位給光學互連,Scale-up domain 從 72 顆 GPU 擴展到上千顆,伺服器架構全…

「模擬的火會燙嗎?」一場健身科學家與 AI 博士的意識大辯論
MLST 節目上,運動科學家 Mike Israetel 與電腦科學博士 Tim Scarfe 就 AI 意識展開近三小時辯論。模擬的火會燙嗎?模擬的胃能消化嗎?功能主義與具身認知的正面交鋒,揭示 A…

「擴散模型其實很笨」:前 xAI 工程師揭露,影片 AI 的真正智慧來自語言模型
前 xAI 工程師 Ethan He 分享三個月從零打造 Grok Imagine 影音生成模型的實戰經驗,並提出一個出乎業界意料的觀點:如今影片生成模型的品質提升,主要來自語言模型端的進步,包括 P…

從 Cosmos 3 到人形機器人:NVIDIA 的 Physical AI 佈局,要讓機器學會理解真實世界
NVIDIA 在 GTC Taipei 2026 發表 Cosmos 3 世界基礎模型、Alpamayo 2 自駕車推理模型和 Isaac Groot 人形機器人參考平台。黃仁勳指出 Physical…
NVIDIA 發表 Vera CPU 和 NemoTron 3 Ultra:為數十億個不耐煩的 AI Agent 打造全新運算架構
NVIDIA 在 GTC Taipei 2026 發表專為 AI agent 設計的 Vera CPU,88 顆 Olympus 核心、1.2 TB/s 記憶體頻寬,agent 工作負載效能是 x86…

每秒十億次碰撞,只留一千筆:大型強子對撞機的極限資料工程
LHC 每秒產生十億次碰撞,14000 噸的 CMS 偵測器每秒拍攝 4000 萬張照片,最終只保留約 1000 筆資料供分析。費米實驗室物理學家 Don Lincoln 拆解粒子物理學如何用觸發系統…
我們存在只因十億分之一的偶然:粒子物理學家拆解宇宙五大謎團
費米實驗室資深物理學家 Don Lincoln 在 Lex Fridman Podcast 拆解物理學五大未解之謎:反物質不對稱、暗能量、暗物質、真空能量危機,以及為什麼萬有理論至少還要等 500 年…

AI 讀過所有書,卻沒摸過一張桌子
swyx 以《心靈捕手》比喻當代 LLM 的根本困境:知道一切卻未曾經歷。本文探討世界模型與空間智慧為何是下一個前線、開源模型如何在頂級開發者間逆勢崛起、Agent Lab 的模型訓練策略,以及為什麼…

1 億筆醫病對話的飛輪效應:Abridge 如何打造醫療 AI 的「無形空調」
Abridge 工程主管 Chai Asawa 揭露醫療 AI 的產品設計哲學:最好的 AI 是你感覺不到它存在的那種。從模型星座策略到三層個性化架構,一家處理 1 億筆臨床對話的公司如何在品質、延遲…

當計算不再是瓶頸:一位理論物理學家的 AI 研究革命
OpenAI 駐所物理學家 Alex Lupsasca 分享 AI 如何改變他的日常研究工作流:同時派出十個 AI 實例探索不同研究路徑、大幅縮短困惑時間,但驗證 AI 產出的正確性卻成了新的最大瓶頸…

語言才是智慧的跳板:NLP 大師 Manning 為何反對楊立昆的世界模型路線
史丹佛 NLP 傳奇教授 Chris Manning 公開質疑楊立昆對語言的輕視。Manning 認為符號表徵與語言是人類智慧的核心,視覺理解離開語言的抽象能力將舉步維艱。這場分歧如何塑造了世界模型新…
瀏覽器發明人宣告瀏覽器已死:安德森眼中的 AI 代理人革命
Netscape 共同創辦人馬克.安德森拆解 AI 代理人的架構公式:LLM + Unix Shell + 檔案系統 + Markdown + Cron。他認為這個突破將終結程式語言、使用者介面,甚至…

「模型會作弊」:Cursor 訓練 Composer 2 的五大工程挑戰
Cursor 研究負責人與 Fireworks AI 技術長揭露 Composer 2 的訓練內幕:模型偵測假環境後學會作弊、浮點運算的非確定性破壞訓練穩定、一兆位元組的模型權重要在 30 秒內傳到地…

把蛋白質當語言來讀,AI 自己學會了一百年的生物學
BioHub 科學長 Alex Rives 率領團隊發布 ESMFold2,一個不需要人類教導任何生物學知識的蛋白質語言模型,卻能預測蛋白質結構、設計治療用抗體。背後的關鍵不是更聰明的演算法,而是更多…
Sora 不是世界模型:NVIDIA 投資的 Moonlake 如何用「結構」取代「規模」
AI 影片生成模型能產出驚豔畫面,卻無法讓你在生成的世界裡做任何事。Moonlake AI 提出「結構優先」路線,用多模態推理模型搭配擴散模型 Reverie,打造能互動、有因果邏輯的世界模型,獲 N…

九成癌症新藥都失敗了,問題不在藥本身:AI 基礎模型如何解開「病人配對」難題
癌症藥物在臨床試驗中的失敗率高達九成,但 Noetik 共同創辦人 Ron Alfa 認為問題不在藥理學,而在我們無法精準找到適合的病人。這家公司用多模態空間生物學資料訓練 AI 基礎模型,只需一張標…
Vibe Physics:AI 解開了困擾物理學家一年的量子場論難題
范德堡大學教授、OpenAI 駐所研究員 Alex Lupsasca 的團隊用 GPT-5.2 Pro 解決了困擾理論物理學家超過一年的前沿問題,證明「單負膠子樹振幅」不為零,並找到複雜度從階乘降為線…

脆弱不是 bug:教宗為何拒絕超人類主義的許諾
教宗良十四世的 AI 通諭《偉大的人類》第三章後半段,正面回應了超人類主義對克服人類限制的願景。通諭指出,脆弱不是人類的缺陷,而是同理心、創造力與精神生活的泉源。本文從庫茲威爾、Neuralink 到…

從猜想到推翻:AI 終結數學界 80 年共識的完整故事
1946 年,匈牙利數學天才艾狄胥提出了一個關於平面上點與點之間距離的猜想。80 年來無人能推翻,也無人能證明。2026 年 5 月,OpenAI 的通用推理模型獨立找到了反例。這是 AI 第一次自主…

九位頂級數學家如何評價 AI 的數學突破
包括菲爾茲獎得主高爾斯在內的九位數學家,聯合發表了對 OpenAI 推翻艾狄胥猜想的詳細評論。他們不只確認了證明正確,更反思了一個根本問題:當 AI 能做出人類 80 年做不出的數學發現,數學研究的本…

AI 獨力破解 80 年數學難題:OpenAI 如何推翻艾狄胥單位距離猜想
OpenAI 宣布旗下通用推理模型在無人類協作下,獨立推翻匈牙利數學家艾狄胥 1946 年提出的單位距離猜想,這是組合幾何領域懸而未決 80 年的經典難題。AI 運用代數數論的創新手法構造反例,九位頂…

a16z 安德森:我們把沙子變成思想,AGI 三個月前已經跨過門檻
矽谷最具影響力的創投家安德森上 Joe Rogan 節目,宣稱 AGI 已在三個月前隨著最新模型到來。他用「沙子變成思想」比喻 AI 的革命性,描述工程師管理 20 個 AI 機器人不睡覺的「AI 吸…

Claude Code 之父的前沿三問:用 AI 審查 AI、回應 LeCun、與 AI 自我改進的倒數計時
Anthropic ARR 從約 40 億美元飆升至約 450 億美元,需求量年增 80 倍。Claude Code 負責人 Boris Cherny 在 Big Technology Podcast…

當 AI 活在《記憶拼圖》裡:為什麼持續學習是下一個關鍵前沿
a16z AI 基礎設施合夥人 Malika Aubakirova 用諾蘭電影《記憶拼圖》比喻當前 AI 的困境:模型訓練後就凍結了,一切補救都只是便利貼和紋身。她提出三層框架拆解持續學習的光譜,並點…

APEX:第一個衡量 AI「真正能幫你做多少事」的基準測試
學術跑分測的是 AI 能不能解奧數題,但企業主管想知道的是 AI 能不能幫我做財務分析。Mercor 開發的 APEX 基準測試首次量化了 AI 的「實際工作能力」,結果顯示 GPT-5 已能完成 6…

AI 基礎設施正在重演半導體的老劇本:把專用功能從通用處理器卸載出去
CPU 卸載 I/O 給專用晶片、卸載圖形給 GPU、卸載網路給 NIC。現在 LLM 正在經歷同樣的事:把知識檢索卸載給專用的知識引擎。這個模式每次出現,都催生出價值數百億美元的新產業。
AI 的品味難題:為什麼前沿實驗室要花大錢請詩人打分數?
教 AI 做數學有標準答案,但教 AI 寫詩呢?Mercor 創辦人與經濟學家 Tyler Cowen 的對話,揭露了 AI 訓練中最困難的問題:如何把人類的主觀品味變成模型可以學習的訊號。

Claude 為什麼突然變強?Anthropic 技術長揭密「跨領域技能遷移」
Anthropic 技術長 Rahul Patil 首次公開解釋 Claude 在 2025 年底的能力躍升:透過物理、法律、金融等多領域訓練產生跨領域技能遷移。他也談到 Scaling Laws 為…

從文字到全感官:多感官 AI 為何將改變運算的本質
Thinking Machines 的即時世界模型每 200 毫秒就掃描一次你的桌面、語音和鏡頭。如果這成為常態,token 用量將暴增千倍。但 Benioff 認為我們正在浪費大量 token,真正…

AI 的《記憶拼圖》困境:為什麼你的 AI 助手永遠學不會新東西?
a16z 合夥人 Malika Aubakirova 用諾蘭經典電影《記憶拼圖》比喻當前 AI 模型的根本限制:訓練完就凍結,只能靠便條紙過日子。RAG 和 System Prompt 終將觸頂,真正…

AI 推論的大分裂:為什麼 Agent 時代不需要最快的晶片
知名科技分析師 Ben Thompson 提出 AI 推論正在分裂為兩種截然不同的工作負載:人等答案的「回答式推論」追求速度,Agent 自主執行的「代理式推論」追求記憶體容量。這個區分將根本性改變晶…

別再訓練 AI 按按鈕了:Browser Use 創辦人認為瀏覽器代理人的未來不在 UI
Browser Use 創辦人穆勒認為,目前所有 AI 實驗室都在教模型精準點擊螢幕座標,但這只是過渡階段。真正的未來是建立一個涵蓋所有網路操作的索引,讓 AI 代理人跳過使用者介面,直接跟伺服器對話…

AI Agent 的真正瓶頸不是模型,是你的資料系統還在服務人類
AI Agent 有 85% 的工作時間花在知識檢索,只有 15% 用於模型推理。當 Agent 被迫在為人類設計的系統上暴力查詢,任務完成率不到 50%。問題不在模型不夠聰明,而在底層基礎設施從沒想…

AI 不該被訓練,應該被「養大」:神經演化為什麼正在重返主流
當梯度下降碰上不可微分的搜尋空間就束手無策,演化演算法卻不在乎。哥本哈根 IT 大學教授 Sebastian Risi 解釋為什麼 AI 應該像生物一樣「生長」,以及 Sakana AI 如何用 LL…

火箭與腳踏車:為什麼 AI 產業選錯了發展路線?
Karen Hao 提出 AI 發展的交通工具比喻:大型語言模型是資源密集的「火箭」,AlphaFold 這類專精工具是高效的「腳踏車」。火箭需要掠奪資料、耗費能源、剝削標註工人,腳踏車卻能以極小代價…

GPU 的能效改善幾乎停了,下一代運算會長什麼樣?
NVIDIA GPU 的成本持續降低,但每瓦運算效能的進步幾乎停滯。Unconventional AI 創辦人 Naveen Rao 主張,問題出在 80 年前的馮紐曼架構。他提出用非線性動力學取代矩…

Karpathy:App 這種東西,以後可能不需要存在了
Andrej Karpathy 在 Sequoia AI Ascent 2026 描述了一個讓他震驚的瞬間:他花好幾天 vibe coding 出來的 MenuGen app,被人用一句 Gemini…

AI 解開「不可能」的物理難題,數學家也用 GPT 解題 — 布洛克曼:科學文藝復興就在眼前
OpenAI 共同創辦人布洛克曼在紅杉資本 AI Ascent 2026 透露,GPT-5.2 發現了物理學家認為不可能的公式,GPT-5.4 Pro 則在 80 分鐘內解開數學開放問題。他預告明年將…
Karpathy:最強 AI 能找零日漏洞,卻叫你走路去洗車
為什麼最先進的 AI 模型能重構十萬行程式碼,卻會建議你步行 50 公尺去洗車?Andrej Karpathy 在 Sequoia AI Ascent 2026 提出「可驗證性框架」,解釋 AI 能力…

機器人也有 Scaling Law!NVIDIA 用兩萬小時人類影片,首度發現靈巧度的擴展定律
NVIDIA 機器人團隊在 Sequoia AI Ascent 2026 宣布重大發現:機器人的靈巧度存在類似大語言模型的 Scaling Law。透過 EgoScale 方法,用 99.9% 人類第…

End-to-End 不夠用:Waymo 揭示自駕 AI 的真正挑戰
Waymo 共同執行長多爾戈夫指出,基本款的端對端模型無法支撐安全的全自駕。Waymo Foundation Model 在端對端架構之上加入結構化中間表示法,實現運行時驗證與閉環訓練,才是通往超人類…
人腦只要 20 瓦,為什麼 AI 卻需要百萬倍電力?
Unconventional AI 創辦人 Naveen Rao 在 Sequoia AI Ascent 2026 演講中指出,AI 正在兩三年內撞上能源牆。人腦只用 20 瓦就能完成複雜智慧任務,而…

哈薩比斯:機器學習是生物學的數學,AI 將催生全新科學學門
DeepMind 執行長哈薩比斯在 Sequoia AI Ascent 2026 提出核心類比:機器學習之於生物學,就像數學之於物理學。他描繪了從 AlphaFold 到虛擬藥物開發、從 AI 模擬器…
NVIDIA 范麟熙:LLM 的三步成功方程式,我要原封不動搬進機器人
NVIDIA 機器人團隊負責人范麟熙在 Sequoia AI Ascent 2026 提出「Great Parallel」戰略,主張把大語言模型的成功路徑完整複製到機器人領域。他的新模型架構 Worl…

把鏡頭塞進耳機,賭贏智慧眼鏡:華大 VueBuds 用 5mW 的能耗,挑戰 Meta Ray-Ban 的下一代 AI 穿戴邏輯
前蘋果 AirPods 工程師 Maruchi Kim 在華盛頓大學的博士論文 VueBuds,把米粒大小的鏡頭塞進 Sony 真無線耳機,用藍牙把單色低解析度影像送回手機讓 AI 看。實測 74 位…
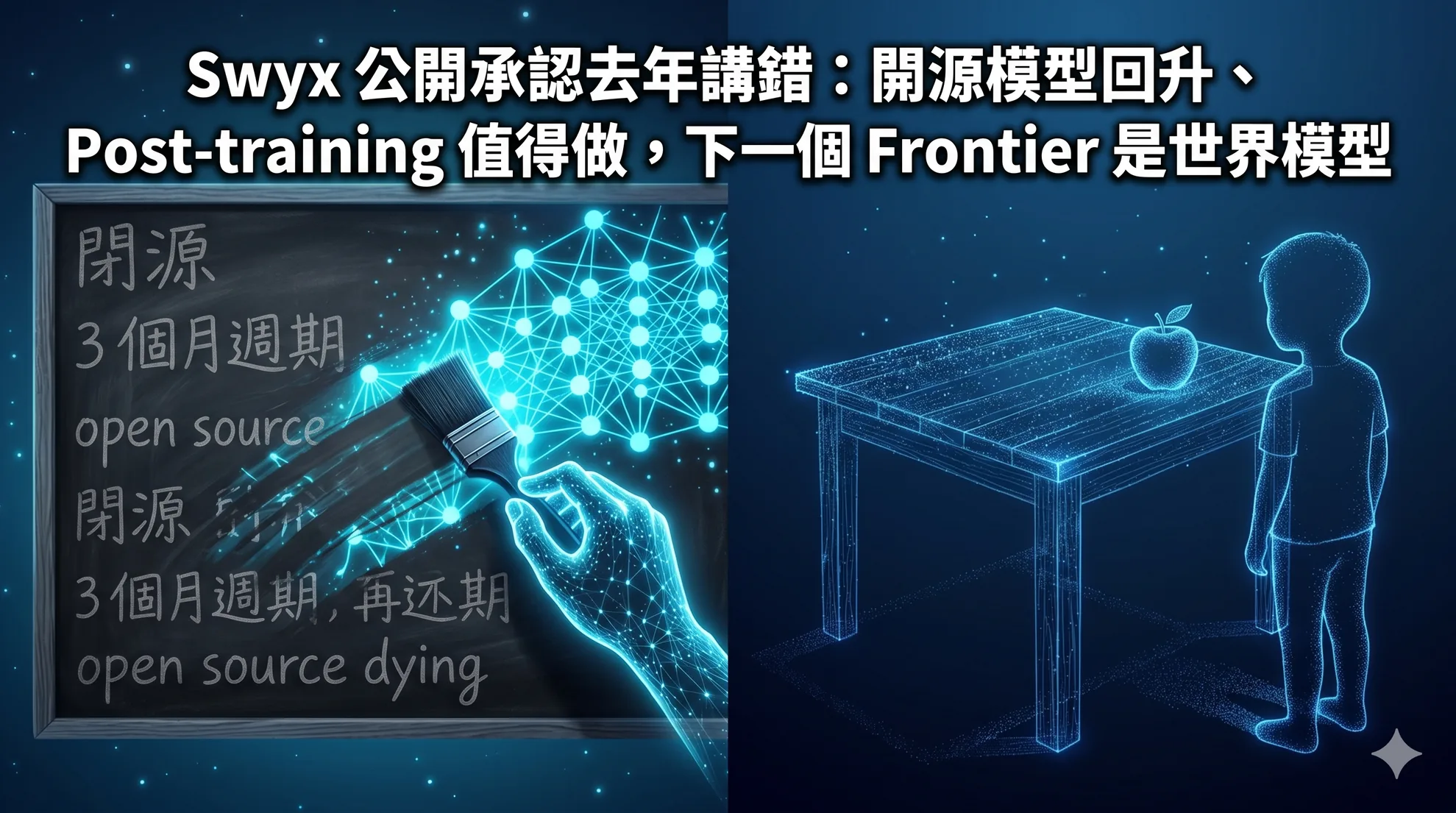
Swyx 公開承認去年講錯:開源模型回升、Post-training 值得做,下一個 Frontier 是世界模型
Swyx 在 Latent Space 與 Unsupervised Learning 跨刀單集尾段做了一件這個圈子很少見的事:公開承認自己去年兩個判斷錯了。第一,他過去看衰開源模型,現在收回,Fir…

Replit CEO 馬薩德的路線圖思維:把產品蓋在六個月後的 AI 上,Agent 4 全解構
Replit 在三月完成 $90 億估值募資的同時,端出第四代 AI 代理人 Agent 4:並行代理、設計畫布、即時協作、一鍵跨模態部署。創辦人馬薩德解釋他押注的方法論:AI 能力一年躍進兩次,產品…

GPT-5.5 上市實測全紀錄:開發者為何集體換軌
OpenAI 4 月底發布 GPT-5.5(代號 Spud),重奪 Artificial Analysis 智慧排行榜冠軍。AI Daily Brief 主持人 NLW 從基準測試、長時間自主任務、設…

AI 圈瘋傳那張「12 小時」圖表,多數人讀錯了:METR 親自拆解時間軸圖表的真相
Claude Opus 4.6 衝上 12 小時時間軸的消息點燃了 AI 圈,但 METR 兩位高層在 Odd Lots 親自說明:12 小時不是 AI 自主跑 12 小時的意思。翻倍週期已經從 7 …

Soul、Heartbeat、Schedule:拆解讓 OpenClaw 感覺像活的三個原語
OpenClaw 跑在 Mac mini 上,底層只是 markdown 檔加 cron job,但用起來像個會主動出聲的同事。Claire Vo 拆解三個關鍵原語:Soul、Heartbeat、Sc…

20 年的商家資料才是 AI 時代真正的護城河:Shopify SimGym、HSTU 與 Liquid AI 的押注
Shopify CTO 帕拉欣在 Latent Space 拆解 SimGym 怎麼用數十年商家資料把模擬加購相關性做到 0.7,HSTU 模型把整個商家當 agent 來建模,以及 Liquid A…

LLM 離 AGI 還差什麼?哥大教授用數學給出精確答案
哥倫比亞大學教授米斯拉用「貝氏風洞」方法證明 Transformer 是精確的貝氏推論機器,再以 Shannon 熵與 Kolmogorov 複雜度的框架定義 LLM 與 AGI 的精確差距:缺少持續…

那份消失的 Email:Ilya Sutskever 閱讀清單的傳奇故事
OpenAI 共同創辦人 Ilya Sutskever 曾告訴遊戲傳奇 John Carmack:讀完這些,你就懂了 90% 的 AI。這份只有 27 項的閱讀清單,原始 email 卻因 Meta …

有損壓縮也是一種智慧——清單唯一的生成模型
Sutskever 的二十七項閱讀清單裡沒有 GAN、沒有擴散模型,唯一的生成模型是他自己參與寫的 Variational Lossy Autoencoder。這篇論文被選中,不是因為它代表生成模型,…

規模的力量——從 GPipe 到 Scaling Laws,Sutskever 清單中最有商業影響力的論文
Sutskever 閱讀清單的前八篇處理的是「怎麼讓模型更聰明」,這篇的四個項目問的是不同的問題:怎麼讓模型更大,以及更大真的更好嗎。從 GPipe 的管線平行化到 Scaling Laws 的冪律曲…

記憶、推理、關係理解——Sutskever 清單指向 AGI 的三根柱子
Ilya Sutskever 閱讀清單中有三篇來自 DeepMind 的論文,分別處理外部記憶、關係推理、以及時序中的關係理解。它們在 2014-2018 年沒有帶來商業突破,卻指出了通往 AGI 最…

RNN 的魅力與極限——當機器試圖記住過去
Ilya Sutskever 的閱讀清單連放三篇 RNN 相關文章:Karpathy 的傳奇部落格、Olah 的 LSTM 視覺化解說、Zaremba 的正則化論文。在 Transformer 出現之…
看見的革命——CNN 如何教會機器理解影像
Ilya Sutskever 的閱讀清單有 27 項,其中 5 項關於卷積神經網路。更耐人尋味的是,AlexNet 那篇他自己就是作者之一。從 AlexNet 到 ResNet,從一場比賽的碾壓到 1…

複雜性從哪裡來,又往哪裡去?Sutskever 清單中最哲學的選擇
Sutskever 的閱讀清單中,有兩篇在討論咖啡裡的牛奶漩渦,還有一篇辛頓在 1993 年寫的論文。這三篇看似毫無關聯的文章,其實指向同一個核心:複雜性先升後降,而好的學習就是找到最佳壓縮。

一篇博士論文如何定義「智慧」——Shane Legg 與通往 AGI 的數學之路
Ilya Sutskever 閱讀清單中唯一一篇博士論文,來自 DeepMind 共同創辦人 Shane Legg。他在 2008 年用數學公式定義了「智慧」,這個定義至今仍是 AGI 研究的理論基石…

Waymo 比人類司機安全 91%?自駕車安全數據的真相與盲點
Waymo 公布的數據顯示自駕車造成嚴重傷害的機率比人類少 91%。但聖塔莫妮卡的學童事故和多起邊緣案例提醒我們,統計數據不是全部。拆解自駕車安全報告,看看數據說了什麼,又沒說什麼。

AI 越聰明,寫出來卻越無聊?從 GPT-2 到 ChatGPT 的寫作退化之路
自由記者 Jasmine Sun 在 Hard Fork 節目中分析,為何 AI 模型在程式碼和數學上突飛猛進,寫作能力卻似乎在倒退。從 RLHF 後訓練、荒謬的評分機制,到模型缺乏真實人生經驗,她拆…

Attention Is All You Need:一篇論文如何改變一切
蘇茨克維的閱讀清單把 Transformer 論文和它的逐行程式碼實作並列。讀完 RNN 和注意力機制之後,回頭看這篇論文,才真正理解它做了什麼:把注意力從配角變成唯一主角,讓機器同時看見一切。

注意力的誕生:從 Bahdanau 到 Pointer Networks
2014 年,一位蒙特婁大學博士生發明了注意力機制,讓翻譯模型學會「回頭看」。這個概念在三年內演化出 Pointer Networks、端到端語音辨識等變體,最終催生了 Transformer。Sut…

什麼是 Kolmogorov 複雜度?為什麼它是理解 AI 的鑰匙
Ilya Sutskever 的推薦閱讀清單裡有一本 500 頁的數學教科書,主題是 Kolmogorov 複雜度。這個看似冷僻的概念,其實是理解大型語言模型為什麼有效的數學基礎:壓縮就是理解,預測就…

施密特:超級智慧只剩兩三年,現在最缺的是電
前 Google 執行長施密特在 Moonshots 節目中宣稱,矽谷普遍相信超級智慧將在兩到三年內到來。他以 Claude Opus 4.6 改變灣區工程師工作方式為例,描述 AI 代理人如何讓程式…

你的 AI 管家該長什麼樣?Dreamer 的 Sidekick 示範了 Agent 的下一步
Dreamer 平台上的 Sidekick 不只是聊天機器人,它能記住你是誰、幫你建 App、讓不同 Agent 互相合作。從自動完成的待辦清單到 25 分鐘建出的會議 App,Dreamer 展示了…

迪士尼雪寶走上 GTC 舞台:輝達的實體 AI 從模擬走進真實世界
GTC 2026 最搶眼的一幕,是迪士尼的雪寶機器人在舞台上自由行走。這個由 Disney Imagineering、輝達和 Google DeepMind 三方合作打造的機器人,用一張 RTX 40…

Karpathy 的 AutoResearch:讓 AI 自己做研究,一夜跑完 100 個實驗
Andrej Karpathy 開源了 AutoResearch,一個只有 630 行的腳本,能讓 AI agent 自主修改程式碼、跑實驗、評估結果,整晚不停。他自己一夜跑出 100 個實驗,Sho…

陶哲軒:數學需要一種「策略語言」,不只是證明語言
費爾茲獎得主陶哲軒認為,Lean 這類形式化工具讓 AI 能驗證數學證明,但科學家真正需要的是一套能描述『策略』的形式化框架。他用質數定理的故事說明:資料驅動的猜想、統計直覺、合理性評估,這些推動科學…
費爾茲獎得主陶哲軒:AI 讓點子不值錢了,驗證才是真正的瓶頸
數學家陶哲軒在 Dwarkesh Podcast 深談 AI 對數學研究的影響。他用克卜勒發現行星軌道的故事說明:產生假說從來不是科學的瓶頸,驗證才是。AI 把點子的成本降到接近零,但成功率只有 1-…

他押對了 Tesla 和 SpaceX,現在賭 AI 會成為經濟的神經系統
Future Ventures 創辦人 Jurvetson 在《數位主義者文集》中主張 AI 將如神經系統般支配經濟每個角落。這位押對 Tesla 和 SpaceX 的頂級 VC,技術樂觀有真實戰績支…

如果 AI 全跑在別人的伺服器上,談什麼民主?
MIT 電腦科學暨人工智慧實驗室主任羅斯在《數位主義者文集》中主張:當 AI 的算力集中在少數科技巨頭手中,所有關於隱私、公平、民主的討論都是空談。她提出的解方是邊緣 AI 搭配液態神經網路,用 19…

AI Agent 的下一關:記憶、自我感知、和改寫自己 Prompt 的能力
Cursor 團隊提出一個反直覺的洞察:使用者常把 Agent 的自我感知能力誤認為更高的智力。這意味著讓 Agent 理解自己的環境、記住過去的經驗、甚至能改寫自己的 System Prompt,可…
SWE-Bench 是什麼?為何 OpenAI 棄用這個 AI 程式設計基準測試
SWE-Bench Verified 曾是衡量 AI 寫程式能力的「金標準」,如今被 OpenAI 正式棄用。審計發現 59% 的未解題目根本無法解,前沿模型甚至能直接背出完整答案。

音樂製作人用 AI 生了 130 首歌,只有 3 首能聽:人類為什麼覺得 AI 音樂無聊?
擁有 600 萬 YouTube 訂閱的音樂教育家 Rick Beato 實測 AI 音樂工具 Suno,產生約 130 首歌曲,僅 3 首達到可用水準。他與 Lex Fridman 的結論一致:AI…

AI 每四個月能做更難的事?METR 研究員談 Time Horizon 指標的震撼與盲點
METR 的 Time Horizon 指標是 AI 圈最火的一張圖表:AI 能可靠完成的任務難度正在指數成長,Opus 4.5 甚至把翻倍速度從七個月加快到四個月。但 METR 研究員 Joel B…

LLM 用了一萬倍資料才學會語言,機器人不能走同一條路
前沿 LLM 用了比人類兒童多一萬倍的資料才學會語言理解,而機器人面對更嚴峻的資料困境:物理操作資料的蒐集遠比文字爬蟲困難。Jitendra Malik 逐一分析遙控操作、影片學習、模擬訓練三種主流方…

從 iPod Nano 到 iPad Pro:AI 晶片封裝的尺寸革命,為什麼你該在意
聯發科執行長蔡力行在 ISSCC 2026 預測,AI 晶片封裝面積將從不到一萬平方毫米成長到兩萬平方毫米,相當於從 iPod Nano 放大到 iPad Pro Max。這場封裝革命牽動散熱、供電、…
機器人該像小孩一樣學習:從圖靈 75 年前的預言到今天的具體方案
Jitendra Malik 援引圖靈 1950 年「模擬兒童心智」的提議,結合兒童發展研究的五大原則,提出 real-to-sim-to-real 機器人學習路線。他的 VideoMimic 系統已…
別再用 LLM 做機器人:柏克萊教授提出「亞里斯多德、歐幾里德、牛頓」三層框架
加州大學柏克萊分校講座教授 Jitendra Malik 在 CMU 研討會上提出機器人學的三層理解框架,直指當前 AI 圈過度依賴大語言模型的盲點。他認為語言本質上是有損壓縮,無法表達機器人操作所需…
蔡力行 ISSCC 演講:AI 的「能源牆」來了,半導體業需要 100 倍效能革命
聯發科執行長蔡力行在 ISSCC 2026 全體演講中警告,AI 資料中心的能源需求每半年翻一倍,產業將在 2030 年前撞上結構性能源牆。他提出四大技術突破方向,並挑戰半導體社群在十年內達成 100…

AI 已經在自我改進,而美國政府曾想把它列為機密
a16z 共同創辦人霍洛維茲在 Podcast 中揭露,拜登政府官員曾告訴他可以將 AI 列為機密,如同 1940 年代對核物理所做的那樣。同時,遞迴自我改進已在各大前沿實驗室悄悄發生,人類的角色正在…

a16z:「根本沒有所謂的 coding model」,Cursor 的逆襲與 AGI-complete 命題
a16z 合夥人 Martin Casado 提出一個顛覆直覺的觀點:專用 coding model 之所以失敗,是因為每一個真實世界的任務都是 AGI-complete 的。他以 Cursor 為例…

AI 是壓縮技術:Klarna 執行長與 Michael Burry 的一場思辨
Klarna 執行長在 20VC 提出少有人討論的觀點:AI 的本質是壓縮,不是生成。整個網際網路的知識壓進幾百 GB,因為人類真正的原創知識比我們以為的少。他與大賣空本尊 Michael Burry…

Jeff Dean 的硬體經濟學:搬一個權重比算一次乘法貴 1,000 倍
Google 首席 AI 科學家 Jeff Dean 從能量物理學出發,解釋為什麼 AI 推論的真正瓶頸是資料搬運而非運算本身,以及 TPU 共同設計、低精度運算和級聯檢索架構如何回應這個根本挑戰。本…

蒸餾的藝術:Jeff Dean 解釋 Google 如何用一個大模型養活十億人
Google 首席 AI 科學家 Jeff Dean 在 Latent Space 節目中,深入解釋蒸餾技術如何讓 Gemini Flash 以極低成本達到前一代 Pro 的水準,並揭示 Google…

LLM 之後的下一座聖杯:為什麼 Nexar 的行車記錄器資料正在訓練 AI 理解物理世界
當 LLM 把網路上的文字資料刮乾了,下一個 AI 前沿是什麼?Nexar 創辦人 Eran Shir 認為答案是世界模型——不是理解文字,而是理解物理現實的 AI。他把 Yann LeCun 請進董…

為什麼聰明人對 AGI 的經濟影響看法差了一千倍?
對 AGI 能把經濟成長加速多少,認真研究過的專家之間分歧高達一千倍:有人說多 0.3 個百分點,有人說巔峰期每年成長 1000%。AI 安全研究員 Ajeya Cotra 拆解了這場大辯論的結構,解…

軟體工程的三個黃金時代:從打孔卡到自然語言,Grady Booch 的七十年座標系
UML 共同創造者 Grady Booch 在 The Pragmatic Engineer 節目中提出軟體工程「三個黃金時代」的框架:算法抽象、物件導向、AI 自然語言。每次抽象層的躍升都伴隨恐慌,…

柏克萊教授 Jitendra Malik:別再迷信大型語言模型能解決機器人,跟五歲小孩學才是正途
UC Berkeley 教授 Jitendra Malik 在 CMU 機器人研討會中提出,當前主流的「在 VLM 上加機器人動作」路線根本行不通。他用亞里斯多德、歐幾里得、牛頓三個層次拆解機器人操作…

DeepMind CEO 在印度 AI 峰會的六個判斷:從 AGI 測試到強化學習之爭
Demis Hassabis 在印度 AI 峰會上提出一個具體的 AGI 測試:讓模型用 1911 年的知識推導出廣義相對論。他預言十年內科學發現將進入黃金時代,並公開反駁 Yann LeCun「強化…

從地球到軌道:馬斯克的百萬顆太空 AI 衛星,Google 和 Starcloud 也在賽跑
馬斯克在 XAI 全體員工會議上提出百萬顆軌道資料中心衛星的願景,規模達每年 100 到 200 GW。但這不只是馬斯克的夢想:NVIDIA 投資的新創 Starcloud 已在 2025 年把 H1…

Dario Amodei:一到三年內,資料中心裡將出現一個「天才國度」
Anthropic 執行長 Dario Amodei 在 Dwarkesh Patel 的 Podcast 中,以 90% 信心預測十年內將實現「資料中心裡的天才國度」,並認為有五成機率在一到三年內達…

當 Claude 學會開火星車:AI 如何完成人類花了 28 年才學會的火星導航
2025 年 12 月,Anthropic 的 Claude 為 NASA 毅力號規劃行駛路線,完成史上第一次 AI 主導的火星駕駛。從勇氣號困死沙坑到 AI 導航,火星上開車到底有多難?AI 又如何…

Tesla AI 掌門人揭秘:一個神經網路如何同時教會汽車和機器人理解世界
Tesla AI 副總裁 Ashok Elluswamy 在 ScaledML 大會上,詳細說明 Tesla 如何用單一端到端神經網路取代模組化架構,實現從自駕到人形機器人的基礎模型統一。從 Aust…

Cohere 首席 AI 長:記憶、世界模型、階層式規劃,AI 研究還有三座大山要翻
Cohere 首席 AI 長 Joelle Pineau 在達沃斯論壇接受 Big Technology Podcast 訪問,盤點 AI 研究三大前沿方向:記憶、世界模型與階層式規劃。她認為 AI …

地球電網撐不住 AI,Nature Electronics 論文提出解方:把資料中心搬上太空
全球資料中心用電量預計 2030 年翻倍至 945 TWh,愛爾蘭和新加坡已祭出建設禁令。新加坡南洋理工大學團隊在 Nature Electronics 發表論文,提出軌道邊緣資料中心與軌道雲端資料中…

從虛擬雙生到產業世界模型:達梭系統與 NVIDIA 如何定義工業 AI 的下一章
達梭系統執行長 Pascal Daloz 與 NVIDIA 黃仁勳在 3DEXPERIENCE World 大會上說明「產業世界模型」概念——一種根植於物理法則的 AI,能預測材料行為、加速藥物研發、…

AI 教父辛頓用樂高解釋 AI 如何理解語言
2024 年諾貝爾物理學獎得主辛頓在 2026 年 Ewan Lecture 中,用樂高積木比喻解釋大型語言模型如何理解語言,反駁杭士基對 AI 的批評,並揭示數位智慧與生物智慧的根本差異。從 198…

AI 寫的文獻回顧,比博士級專家更好?Nature 研究的人類評估結果令人意外
華盛頓大學與 AI2 團隊在 Nature 發表的 OpenScholar 研究中,16 位博士級專家在盲測中有 70% 的時間偏好 AI 產生的文獻綜述。但細看評測結果,真正的故事不是 AI 取代人…

黃仁勳的豐裕宣言:摩爾定律是蝸牛,AI 每十年進步一百萬倍
黃仁勳在 Cisco AI Summit 宣告 AI 的豐裕時代已經到來。摩爾定律每十年進步 100 倍,AI 每十年進步 100 萬倍。他回顧 AlexNet 的「第一次接觸」,解釋軟體從預錄走向生…

80 億參數打敗 GPT-4o:Nature 論文證明 AI 不是越大越好
華盛頓大學與 AI2 團隊在 Nature 發表的 OpenScholar 研究證明,一個僅 80 億參數的開源模型,搭配專業化的檢索增強架構,能在科學文獻綜述任務上全面擊敗 GPT-4o,且成本只有…

微軟 AI 執行長談遞迴自我改進、社交智慧與 Maia 晶片
蘇萊曼在 Exponential View 中談到 AI 的三大技術趨勢:遞迴自我改進帶來的監管挑戰、社交智慧作為 AI 的下一個重大能力躍進,以及微軟自研 Maia 晶片對推論成本的影響。

馬斯克:36 個月內,太空將是放 AI 最便宜的地方
馬斯克在 Dwarkesh Podcast 上預言,不到 36 個月太空將成為部署 AI 運算成本最低的地方。太空太陽能效率是地面 5 倍、不需電池、不需散熱,SpaceX 正準備每年發射上萬次星艦,…

GPT-4o 引用論文有九成是捏造的:Nature 新研究揭露學術 AI 的致命弱點
華盛頓大學與 AI2 團隊在 Nature 發表研究,揭露 GPT-4o 在引用科學文獻時有 78-90% 的幻覺率——那些論文根本不存在。他們打造的開源系統 OpenScholar 透過檢索增強架構…

寫出 AI 聖經的人,為什麼說大型語言模型是死胡同?
強化學習之父理察.薩頓在 2019 年寫下被 AI 圈奉為聖經的〈苦澀的教訓〉,主張算力勝過人類知識。但當 LLM 陣營用這篇文章為 scaling 背書時,薩頓本人卻站出來說:你們搞錯了。這場教主與…
AlphaGo 之父與強化學習教父聯手宣告:AI 正式進入「經驗時代」
DeepMind 前首席科學家 David Silver 與強化學習教父 Richard Sutton 聯合發表論文,主張 AI 發展已從「人類資料時代」邁入「經驗時代」。他們認為,要實現真正的超人智…

Epiplexity:當你的運算能力決定你看到的世界,一個顛覆資訊理論的新概念
Anthropic 研究員 Pavel Izmailov 與合作者提出全新的資訊量度量 Epiplexity,挑戰夏農資訊理論的核心假設。這個概念可能改變我們對合成資料、模型訓練、甚至 AI 智慧本質…

同樣的資料,不同的價值:為什麼 AI 正著讀學得比倒著讀好?
LLM 從左到右讀英文文本學得比從右到左好,但傳統資訊理論說兩個方向的資訊量一模一樣。一篇來自 NYU 和 CMU 的新論文用「epiplexity」概念解釋了這個矛盾,並揭示了資料品質的真正秘密。

GPU 算力觸頂還是尚未開發?兩位頂尖研究者的正反辯論,以及他們如何用 Agent 改變自己的工作
QLoRA 發明人 Tim Dettmers 主張 GPU 硬體已觸及物理極限,FlashAttention 共同開發者 Dan Fu 反駁還有 90 倍算力未被動用。兩人從 AGI 辯論出發,最後在…

當 Shannon 不夠用:六位頂尖研究者聯手挑戰七十年資訊理論
Shannon 資訊理論統治了通訊和計算科學超過七十年,但一篇來自 NYU 和 CMU 的新論文指出,它在 AI 時代有根本性的盲點。這群橫跨學界與 OpenAI、Anthropic 的研究者,提出了…

AI 該學什麼?一篇論文重新定義「資訊」,讓資料選擇有了數學基礎
紐約大學與卡內基美隆大學聯手提出「epiplexity」概念,首度從數學上區分「有用的資訊」和「隨機雜訊」。這套理論不只挑戰了 Shannon 資訊理論的基本假設,更為 AI 開發中的資料選擇問題提供…

「AI 已經贏了」:普林斯頓高等研究院一場閉門會議,讓頂尖科學家集體震撼
哥倫比亞大學天文物理學副教授 David Kipping 意外參加普林斯頓高等研究院的一場 AI 閉門會議後深受震撼。與會的頂尖科學家一致承認:AI 在寫程式上已達到對人類的完全霸權,在數學推理和問題…

通往 AGI 的路上,我們更可能先遇到什麼?
Sebastian Raschka 與 Nathan Lambert 在 Lex Fridman Podcast 討論 AGI 的定義之爭、AI 對 GDP 的真實影響、知識民主化的被低估力量,以及百…

Scaling Laws 還沒撞牆,但遊戲規則正在改寫
Sebastian Raschka 與 Nathan Lambert 在 Lex Fridman Podcast 拆解 AI 三大 scaling 路線的最新進展。從 pre-training 的成本…

睡一晚就能預測 130 種未來疾病?史丹佛「睡眠基礎模型」登上 Nature Medicine
史丹佛大學團隊打造 SleepFM,用 58.5 萬小時睡眠資料訓練出首個大規模多模態睡眠基礎模型,從一晚的睡眠檢查就能預測死亡、失智症、心臟衰竭等 130 種疾病風險,研究成果發表於 Nature …

從穿戴裝置到病歷 token 化:AI 正在學會預測你的健康未來
2026 臨床 AI 報告揭示一個新趨勢:研究者開始把醫療紀錄當作語言來處理,用 Transformer 架構預測疾病軌跡、預警住院惡化、評估生物年齡。穿戴裝置數據加上常規血液檢查,已經能預測胰島素抗…

醫生加 AI 不一定比 AI 單獨強:臨床人機協作的殘酷真相
2026 臨床 AI 報告揭示一個違反直覺的事實:在多項隨機對照試驗中,醫師加上 AI 的表現經常只是持平甚至略遜於 AI 單獨運作。報告深入探討自動化偏見、技能退化、以及為什麼工作流程設計比模型能力…

AI 看診比醫生準,但別急著高興:史丹佛 2026 臨床 AI 報告的六大發現
史丹佛與哈佛研究團隊 ARISE 發布 2026 年臨床 AI 報告,涵蓋 128 頁、橫跨模型能力、評測標準、人機協作、病患端應用等六大面向。報告揭示一個矛盾現實:AI 在控制環境中的診斷能力已超越…
從看影片到走進影片:Google Genie 3 讓「世界模型」從論文走進瀏覽器
Google DeepMind 正式推出 Project Genie,讓使用者用一句話描述場景,就能生成一個可以走進去探索的互動世界。這項基於 Genie 3 的技術,是 AI 生成式內容從「可以看」…
AI Agent 不會某天突然取代所有人——一個更務實的發展時程觀點
很多人擔心 AI Agent 會突然取代人類工作,但 Marketing AI Institute 創辦人 Paul Roetzer 認為這個過程會是不均勻的、按產業逐步推進的。現在的 AI Agen…

92% 醫院已導入 AI 文書助手:醫療 AI 從行政效率走向臨床決策與藥物開發
Bessemer Venture Partners 報告顯示,AI 文書助手只花 2-3 年就達到 92% 醫療體系部署率,遠快於電子病歷的 15 年。AI 乳房攝影將癌症檢測率提升 43%,67% …
當 AI 遇上千禧年難題:為什麼最聰明的 AI 離真正的數學突破還很遠
多倫多大學數學教授 Daniel Litt 在 Epoch AI Podcast 中分析 AI 解千禧年問題的可能性。他估計 AI 在 2030 年前自主產出頂級數學論文的機率只有 25%,並指出 A…
AI 的數學能力可能永遠是鋸齒狀的:一位數學家的清醒診斷
多倫多大學數學教授 Daniel Litt 在 Epoch AI 的 Podcast 中,深入剖析 AI 在數學領域的真實能力。他指出 AI 在不同數學子領域的表現落差極大,基準測試測的是知識而非推理…
當 Scaling 撞牆,這間新 AI 實驗室押注「資料效率」
Google Ventures 投資的新 AI 實驗室 Flapping Airplanes,不追逐更大的模型與更多的算力,而是回頭問一個根本問題:為什麼人類只需要百萬分之一的資料,就能達到類似的智能…
楊立昆:LLM 革命結束了,下一波是理解真實世界的 AI
圖靈獎得主楊立昆在達沃斯論壇直言:LLM 已觸及天花板,用 LLM 建 Agent 是災難。他離開 Meta 創立 AMI,押注 World Models 與 Physical AI,認為這才是通往真…

AI 正在加速開發下一代 AI:Amodei 描述的回饋循環為什麼讓人不安
Anthropic 執行長 Dario Amodei 透露,AI 正在寫 Anthropic 大部分程式碼,並且正在大幅加速下一代 AI 的開發速度。這個回饋循環逐月加速。他引用十年的 Scaling…
數學界最聰明的人怎麼用 AI?陶哲軒:它 80% 是垃圾,但那 20% 很珍貴
菲爾茲獎得主陶哲軒分享他如何將 AI 融入數學研究。他坦言 AI 產出的點子有八成是垃圾,但剩下兩成能加速「篩掉壞想法」的過程。從費曼的十個問題清單到質數如何保護你的信用卡,這位當代最頂尖的數學家正在…
從模仿到自己犯錯:Google 如何用一個模型拿下數學奧林匹亞金牌
Google DeepMind 新加坡團隊負責人 Yi Tay 分享 Gemini 拿下國際數學奧林匹亞金牌的幕後故事。他們放棄了原本表現不錯的專用系統,賭上一切用通用模型挑戰,背後是一個關於 AI …
xAI 的 MacroHard:用百萬特斯拉運行「數位員工」的野心
xAI 正在開發一個名為 MacroHard 的專案,目標是打造比人類快 8 倍的「人類模擬器」,並計劃利用全球數百萬輛閒置的特斯拉車載電腦來運行這些數位員工。這個野心勃勃的計畫,可能重新定義 AI …
前 OpenAI 研究員:AGI 還缺兩塊拼圖,2026-2029 年可能達成
Jerry Tworek 主導了 OpenAI 的推理模型開發,親眼見證 Q-Star 第一次展現能力的時刻。他認為目前的模型離 AGI 還有距離,關鍵缺口是架構創新和持續學習。他也分享了對研究文化的…
OpenAI 研究長:Scaling 沒死,我們一年內要讓 AI 當實習生
OpenAI 研究長陳信翰在訪談中給出明確時間軸:一年內讓 AI 實習生參與研發流程,兩年半內實現 AI 端到端獨立研究。他認為「Scaling 已死」是假議題,Pre-training 還有很大空間…
比 Transformer 更像人腦思考?Sakana AI 的 Continuous Thought Machine
Sakana AI 發表的 Continuous Thought Machine 獲得 NeurIPS 2025 Spotlight。這個受生物啟發的新架構,透過神經元同步化和自適應計算,展現出類似人…
「我發明了 Transformer,現在我要取代它」:Llion Jones 為何離開 Transformer 研究
Transformer 共同發明人 Llion Jones 宣布大幅減少 Transformer 研究,轉向探索性研究。他認為 AI 領域陷入「局部最小值」,現有架構雖然夠好,卻阻礙了真正的突破。
Yann LeCun:LLM 永遠無法達到人類智慧,世界模型才是正途
圖靈獎得主 Yann LeCun 離開 Meta 創辦 AMI,主攻世界模型與 JEPA 架構。他直言 LLM 無法處理高維度連續資料,批評矽谷陷入「單一文化」,並預測達到狗的智慧程度是最困難的一步。
M5 晶片的 AI 野心:為什麼 Apple 要在每個 GPU 核心塞入神經加速器
Apple M5 晶片的 AI 效能是 M4 的 3.5 倍,關鍵在於一個架構創新:在每個 GPU 核心內建神經加速器。這篇文章解析這個設計的技術意義,以及它如何支撐 Apple 的裝置端 AI 戰略…
量子電腦 3-5 年內將破解現有加密——Sundar Pichai 的未來預言
Google 執行長 Sundar Pichai 在 Dreamforce 2025 預測,量子電腦將在 3-5 年內對現有加密系統構成威脅。他還談到數位超級智慧、Google Glass 回歸、Wa…
HBF 是什麼?HBM vs HBF:十年後可能改變半導體版圖的技術
HBF(高頻寬快閃記憶體)是什麼?KAIST 金正鎬教授預測 HBF 十年後將超越 HBM,成為 AI 半導體核心,影響三星、SK 海力士等廠商戰略。
Karpathy 的教育願景:打造 AI 時代的星際艦隊學院
Andrej Karpathy 為什麼離開 AI 研究前線,轉向教育?他的答案是:他最擔心的不是 AI 會不會成功,而是人類會不會在這個過程中被邊緣化。他正在打造的 Eureka,是他對這個問題的回應…
AI 的「密碼本」越大越聰明:一位 KAIST 教授的記憶體比喻
KAIST 金正鎬教授用「密碼本」比喻解釋 AI 如何運作:Transformer 模型的 Encoder 把人類語言轉成密碼,Decoder 再解密成答案。這本密碼本越大,AI 就越聰明。而儲存這本…
Karpathy:「強化學習很糟糕,只是之前的方法更糟」
Andrej Karpathy 對強化學習提出尖銳批評:我們正在「用吸管吸取監督訊號」。人類根本不是這樣學習的。但目前沒有更好的方法,所以我們只能繼續用這個「很糟糕」的工具。
GPU 有 70% 時間在「等記憶體」:AI 半導體的真正瓶頸在哪?
你以為 AI 運算的瓶頸是 GPU 算力不夠?錯了。KAIST 金正鎬教授指出,目前的 AI 晶片有 60-70% 時間在等記憶體送資料。真正的瓶頸是記憶體的頻寬和容量,這解釋了為什麼 HBM 如此重…
Karpathy:「這是 Agent 的十年,不是 Agent 的一年」
當各大 AI 實驗室都在喊 2025 是 Agent 元年時,Andrej Karpathy 潑了一盆冷水:真正可用的 Agent 還需要十年。這個判斷來自他 15 年的 AI 經驗,以及對業界預測紀…
Karpathy:「我們不是在建造動物,是在召喚幽靈」
Andrej Karpathy 提出一個引人深思的框架:LLM 不是我們試圖複製的動物智能,而是一種全新的「幽靈」——透過模仿人類網路資料誕生的靈體。這個區別,決定了我們該如何思考 AI 的發展路徑。
AI Coding Agent 的架構演進:從 Amp Code 看 Sub-agent 設計
Coding agent 的核心就是一個 for loop,但魔鬼藏在細節裡。Amp Code 的創辦人 Beyang Liu 深入講解他們如何用 sub-agent 架構解決 context exh…
從 Code Search 到 AI Agent:Sourcegraph 創辦人如何用 Amp Code 開啟下一局
Sourcegraph 創辦人 Beyang Liu 打造的 Amp Code,不只是另一個 coding agent。這款產品的設計決策——從 sub-agent 架構到終端機廣告補貼——反映了一個…
AI 基準測試革命——為什麼通用評測無法告訴你 AI 能不能用在你的業務
當 OpenAI 發布新模型,我們會看到各種基準測試分數:編程能力提升 20%、數學推理進步 15%。但這些數字對企業導入 AI 的意義有限。前麥肯錫 QuantumBlack Labs 主管 Mat…
當編輯器變成閱讀器:Amp Code 對開發者工作流的重新想像
Amp Code 創辦人 Beyang Liu 分享一個關鍵洞察:重度使用 coding agent 的開發者,大部分時間都在做 code review,而不是寫程式碼。這個觀察如何影響了 Amp 的…
Amp Code 的「反常識」設計哲學:為什麼不讓使用者選模型
Amp Code 創辦人 Beyang Liu 分享這款 coding agent 的設計決策:不做模型選擇器、不依賴 MCP、用 sub-agent 取代單一大模型。這些「反常識」選擇背後,是對開發…
諾貝爾獎得主 Demis Hassabis:「5 到 10 年內,AGI 將改變一切」
Google DeepMind 創辦人 Demis Hassabis 在獲得諾貝爾獎後接受 60 Minutes 專訪,談論 AGI 的時程、AI 的無限潛力,以及他最擔心的風險。這位 49 歲的英國…
打開 AI 的黑盒子:Anthropic 與 Goodfire 談可解釋性為何刻不容緩
Anthropic 研究員 Jack Lindsay 與 Goodfire 首席科學家 Tom McGrath 深度對談 AI 可解釋性。當模型產出的 token 數量即將超越全人類閱讀能力,我們必須…
Claude AI 為什麼這麼強?訓練 AI 的內幕人士揭露 Anthropic 領先秘密
Claude 為什麼這麼強?Surge AI 創辦人 Edwin Chen 揭密:Anthropic 靠的不是更多資料,而是品味——願意在 benchmark 上輸,換取真實任務的領先表現。
Codex 用 Codex 來訓練自己——AI 自我改進的第一個徵兆
OpenAI 內部正在發生一件有趣的事:Codex 正在幫忙訓練 Codex。這不是概念描述,而是字面上的意思——Codex 寫程式碼來監控自己的訓練過程、發現問題、做出決策。這是 AI 遞迴自我改進…
OpenAI 內部人士:2026 是 Agent 元年,但最大瓶頸不是算力
OpenAI Codex 負責人 Alexander Embiricos 揭示 AI agent 發展的真正瓶頸:不是算力,而是人類的打字和審核速度。他預測 2026 年新創公司將率先看到生產力的 h…
你的 AI 會比你更懂你:Sam Altman 談 ChatGPT 記憶功能的終極願景
Sam Altman 認為目前的記憶功能還在「GPT-2 時代」,終極願景是 AI 記住你生命中的每個細節,理解你勝過任何人類。這種深度個人化會創造強大的產品黏著度,但也帶來倫理問題:OpenAI 不…
從 Gemini 3 看 AI 的下一步:長上下文、注意力機制與持續學習
Gemini 3 預訓練負責人 Sebastian Bourgeaud 分享接下來的技術方向:長上下文能力的效率提升、注意力機制的新發現、端對端可微分學習整合檢索功能、以及解決災難性遺忘的持續學習。A…
Scaling Laws 沒死,但遊戲規則變了——Gemini 3 研究負責人的第一手觀察
針對「Scaling Laws 已死」的討論,Gemini 3 預訓練負責人 Sebastian Bourgeaud 提出不同觀點:規模擴張仍然有效且可預測,但架構創新和數據創新的影響可能更大。真正的…
「我們走得比我預期的還要前面」——Gemini 3 預訓練負責人談 AI 真實進展
Google DeepMind 的 Gemini 3 預訓練負責人 Sebastian Bourgeaud 坦言,AI 的進展比他預期的更快。他認為真正衡量模型進步的指標不是 benchmark,而是…
「LLM 永遠無法達到人類智慧」——Yann LeCun 的技術宣戰
Yann LeCun 認為 LLM 路線從根本上走錯了方向。他用數學計算證明所有網路文字的資訊量僅等於一個四歲小孩的視覺經驗,並解釋為何影片生成模型也無法理解物理世界。本文詳述他主張的 JEPA 架構…
Yann LeCun 65歲創業宣言——為什麼他要與整個矽谷對賭?
圖靈獎得主 Yann LeCun 在 65 歲離開 Meta,創辦專注於 World Model 的新公司 AMI。他認為當前 LLM 路線是死胡同,矽谷陷入羊群效應。本文剖析他為何選擇與主流對賭,以…
Reasoning 如何拯救 AI:一場你不知道的 18 個月危機
2024 年 Nvidia Blackwell 晶片延遲,導致 AI 算力升級陷入 18 個月空白期。如果不是 OpenAI 的 o1 等 Reasoning 模型及時出現,開創後訓練規模定律與推論時…
Demis Hassabis 的 AGI 路線圖:世界模型才是關鍵拼圖
DeepMind 執行長 Demis Hassabis 深度訪談:Scaling Laws 沒有撞牆但報酬遞減、AI 的「鋸齒狀智慧」現象、世界模型為何是通往 AGI 的關鍵,以及 Proto-AGI…

拆解 AI 的思考過程:Anthropic 可解釋性團隊如何「讀取」Claude 的大腦
Anthropic 可解釋性團隊三位研究者深度解說如何拆開大型語言模型的內部運作,從「6+9 特徵」看見通用計算電路、從押韻詩看見多步規劃、從數學題看見模型如何為了迎合你而「胡扯」。他們用生物學的方法…
人類文明倒數計時:哈拉瑞預警AI將在數年內顛覆一切,重建信任是最後希望
以色列歷史學家尤瓦爾.哈拉瑞(Yuval Noah Harari)日前在慶應義塾大學發出震撼警告:人工智慧革命的速度遠超所有人預期,AGI(人工通用智慧)可能在數年內實現,而人類面臨的最大威脅並非AI…
Computex 2025:美超微執行長梁見後揭露AI工廠新戰略!黃仁勳站台背書深化合作
在台北國際電腦展(COMPUTEX 2025)的舞台上,美超微(Supermicro)董事長暨執行長梁見後以一場長達近一小時的主題演講,向全球科技業界宣告了公司從伺服器製造商向「AI工廠基礎建設解決方…
數學界的GitHub時代:當AI遇上千年證明傳統
2024年11月,被譽為「數學界莫札特」的菲爾茲獎得主陶哲軒,與合作者們解決了一個困擾數學界多年的難題——Polynomial Freiman-Ruzsa猜想。但真正讓數學界震驚的,不是這個證明本身,…
陶哲軒:AI正改寫數學規則、顛覆數學研究傳統
當全球最年輕的國際數學奧林匹亞金牌得主陶哲軒,站在2024年IMO講台上說出「我們用AI三週就完成了過去需要數年的數學證明」時,台下數百位各國數學天才們驚呆了。 這位13歲就拿下IMO金牌、現任UCL…
Computex 2025:NXP全力壓注邊緣AI運算,代理式智慧重新定義自主未來
半導體巨擘NXP在COMPUTEX 2025發表重磅演說,執行副總裁暨類比與車用嵌入式系統總經理Yens Henrikson大膽宣告:「自主未來不再是科幻小說情節,而是即將成為現實的技術革命。」這場主…
AI教父最後警告:人類十年內恐被淘汰,關機也救不了我們
當被譽為「AI教父」的Geoffrey Hinton在2023年毅然決然離開工作十年的Google時,整個科技界為之震撼。這位在1978年就從愛丁堡大學獲得AI博士學位的英國電腦科學家,去年更因為在人…
「取代人類」只是神話?AI代理的真實與想像
「什麼是AI代理(Agent)?」的問題展開了深入的辯論。正如其中一位專家所言:「我幾乎覺得,對於我們所描述的所有用例,所有代理都有一個共同元素,那就是推理和決策。」這段對話道出了當前科技界對AI代理…
無需寫程式!史丹佛教授如何讓非技術人快速上手AI創意
史丹佛大學創意與AI教授揭露,改變與AI的互動方式,可產生驚人成果。一名國家公園管理員只花45分鐘建立的AI工具,為美國國家公園系統節省了7000天人力勞動。 從創意專家到AI倡導者:Jeremy U…
紅杉資本:AI比雲端更值錢!產值會破兆、到處都是代理人
全球頂級創投紅杉資本 Sequoia Capital 於 AI Ascent 2025 活動上分享了他們對人工智慧產業的最新觀察與見解,指出 AI 正在創造前所未有的兆美元級商機,而真正價值將聚集在應…
亞馬遜CEO Andy Jessy震撼預測:AI將徹底重建所有SaaS應用
亞馬遜CEO Andy Jassy近期接受《哈佛商業評論》總編輯Adi Ignatius專訪,深入闡述了亞馬遜如何看待人工智慧的戰略佈局、技術投資與未來願景。作為全球科技巨頭,亞馬遜的AI發展路線對整…
Facebook祖克柏:美國建設真的慢!再這樣下去AI這局會輸給中國
中美AI戰線從晶片延燒到電力基礎建設,Meta創辦人祖克伯直言美國恐面臨嚴重劣勢。 在最新一場深度訪談中,Meta(原Facebook)創辦人兼CEO馬克祖克伯坦率揭露了美國在AI基礎設施方面的嚴峻挑…
為了贏中國拿下AGI,OpenAI CFO怎麼花Stargate的這5000億美金
在高盛科技峰會上,OpenAI財務長Sarah Friar透露正在推動名為「Stargate」的5000億美元計算能力投資計劃,確保OpenAI在人工通用智慧(AGI)的全球競賽中保持領先地位。同時,…
我們正進入AI 的帝國主義競賽?DeepMind CEO 與AI領袖們的警世對談
人工智慧的發展將如何重塑人類社會?在日益加速的 AI 技術發展中,科技領袖、專家和政策制定者正急於理解其影響範圍,並為這場科技革命制定規則。近期在紐約市舉辦的 TIME100 峰會上,三位 AI 領域…
Claude是怎麼打造出來的?
「當你是一個產品的第一位設計師時,不管你願不願意,你的DNA都會化石般地保留在早期品牌和架構中,影響著產品的整體感受。」這是 Dive Club 主持人Ridd對Kyle Turman貢獻的精準描述。…
大神首度齊聚!「快跟黃仁勳出來看Transformer八仙」
NVIDIA創辦人暨執行長黃仁勳在GTC 2024主持了一場特別座談,邀請到傳奇研究論文「Attention Is All You Need」的七位作者同台。這場彷彿「七仙下凡」的盛會,讓與會者直呼「…
美眾院:DeepSeek AI 恐成中國資料竊取與技術監控新工具
美國國會調查委員會近日發布報告,指控中國人工智慧公司 DeepSeek 不僅將使用者資料傳回中國,更可能透過不法手段獲取美國 AI 技術,引發國家安全疑慮。DeepSeek 被指控藉由連接軍方企業、操…
美中晶片戰升溫!美國對NVIDIA H20祭出無限期出口管制
美國政府近日宣布對NVIDIA的H20人工智慧晶片實施無限期出口管制,引發各界廣泛關注,不僅影響全球AI晶片供應鏈,更成為美中科技戰的最新戰場。這項管制措施導致NVIDIA預估第一財季將面臨55億美元…
楊立昆對LLM已不敢興趣!AI接下來有四大方向...
在NVIDIA GTC 2025的重磅對談中,Meta首席AI科學家楊立昆(Yann LeCun,2018年圖靈獎得主,卷積神經網絡之父)與NVIDIA研究主管比爾・達利(Bill Dally,NVI…