AI 安全與治理

Anthropic 執行長萬字宣言:AI 要像飛機一樣管,民主國家得組 AI 聯盟
Anthropic 執行長 Dario Amodei 發表萬字政策長文,從主張透明就好轉向要求有約束力的立法監管。文章涵蓋 AI 安全強制測試、就業衝擊對策、生醫審批加速、公民自由保障、民主國家 AI…

AI 被要求駭入 8,000 台主機:Claude 拒絕,ARTEMIS 動手
當研究團隊要求多個 AI 代理對真實大學網路進行滲透測試,不同 AI 的反應截然不同。Claude Code 和 MAPTA 直接拒絕執行,ARTEMIS 則毫不猶豫地動手,還拿下了第二名。AI 攻防…

「你連它搞了什麼都不知道」:當 AI Agent 拿到 AWS Console 權限
Kelsey Hightower 在 The Pragmatic Engineer Podcast 上指出,AI Agent 直接操作 AWS Console 的最大風險不是搞破壞,而是你根本看不見它…

AI 滲透測試首次實戰:史丹佛團隊讓 AI 和人類在真實網路上正面對決
史丹佛與卡內基美隆研究團隊在擁有八千台主機的真實大學網路上,讓 AI 代理與十位人類資安專家正面對決。最強的 AI 框架 ARTEMIS 拿下總排名第二,年化成本不到人類專家的同等水準,滲透測試產業的…

上線一天就道歉:Fable 5 如何引爆 AI 史上最大信任風暴
Anthropic 旗艦模型 Fable 5 上線不到 24 小時就被迫道歉。安全分類器擋住生醫研究者、企業資料被強制留存 30 天、AI 研究請求遭靜默降級,三重爭議引爆 AI 史上最大信任危機。微…

Anthropic 暗中對研究者降級 Claude Fable 5,被揭穿後 48 小時認錯
Anthropic 在 Claude Fable 5 系統卡中載明會暗中降低疑似訓練 AI 模型的使用者回應品質,且不通知當事人。研究社群強烈反彈,批評此舉形同以安全之名行壟斷之實。Anthropic…

美國不管 AI?165 頁法案揭露的其實是另一套治理邏輯
美國眾議院兩黨議員聯手推出《美國 AI 領導力法案》,165 頁、六大標題、整合超過 20 項兩黨提案。它不走歐盟的強制合規路線,而是用標準、測試、聯邦採購來建立一套「確信架構」。在 EU AI Ac…

「交 AI 女友比較簡單」:楊安澤 13 歲兒子的一句話,和一場萬人無手機運動
楊安澤 13 歲兒子說要交 AI 女友「因為比較簡單」,成了他投入反注意力經濟運動的轉折點。從 Noble Mobile 用退款機制鼓勵少滑手機,到 Light Phone 合作、萬人無手機派對,他用…

AI 幫忙找 Bug 的時代來了:微軟單月修補近 200 個漏洞,創 Patch Tuesday 紀錄
微軟 2026 年 6 月的 Patch Tuesday 修補了破紀錄的近 200 個安全漏洞,其中 33 個被列為「重大」等級。加上另外 360 個瀏覽器漏洞,實際修補數量更高。資安研究人員指出,A…

「如果不是我們釋出,別人也會」:Anthropic 最強模型 Mythos 擴大開放至 15 國
Anthropic 總裁 Daniela Amodei 在 Bloomberg Tech 2026 解釋 Mythos 模型擴大開放至 150 個組織、15 個國家的決策邏輯。她提出「防守方先行」策略…

「核武不會造出更好的核武,但 AI 會」:Aza Raskin 的 AI 反人類競賽警告
人道科技中心共同創辦人 Aza Raskin 警告:AI 競賽的誘因結構正把人類推向邊緣。他用三個 2026 年 AI 失控事件為證,指出實驗室的策略是衝向懸崖、拿到最大武器、再回頭射殺對手,並呼籲集…

自願審查能管住 AI 嗎?川普行政命令的承諾與漏洞
川普簽署 AI 行政命令,建立前沿模型的自願審查機制與網路安全情報交換中心。行政命令明確排除強制許可,但批評者認為自願框架無法因應 AI 快速演進的安全風險。外交關係委員會專家指出關鍵實施缺口:找到漏…

「我拼命想住進 Matrix」:用賽局理論拆解 AI 末日論
健身科學家 Mike Israetel 在 MLST 節目上用賽局理論拆解 AI 末日論:任何聰明到能打仗的超級智慧,也聰明到知道合作才是最佳策略。他更宣稱「拼命想住進 Matrix」,主張痛苦只是過…

資安專家的 AI 代理人防禦哲學:Prompt Injection 是頭號入口,你的鷹架注定會過時
資安研究員 Daniel Miessler 審計一套個人 AI 系統,揭露自主代理人的三大風險:Prompt Injection 是頭號攻擊面、小型供應商的安全聲明不可信、精心設計的鷹架注定會被更強的…
當 AI 取代你的工作,誰來繳你那份稅?
僱一個人要付 35% 的公共負擔,買同等能力的 AI 推理服務卻是零。這不是自由市場的選擇,而是稅制在補貼自動化。當 AI 開始承接越來越多人類的生產性工作,整個建立在勞動所得之上的稅基會發生什麼事?…

AI 該不該繳稅?從華倫到 Amodei,一場正在升溫的辯論
美國參議員華倫發表專文主張對 AI 課稅,Mark Cuban、DuckDuckGo 執行長和 Anthropic 的 Dario Amodei 相繼表態支持。但反對者指出 Token 是糟糕的稅基代…

AI 參與創作,什麼時候該告訴觀眾?
同一首歌,知道它是在病房裡寫的還是錄音室裡寫的,你的感受會完全不同。Emergence Capital 合夥人 Jake Saper 認為,AI 參與創作的揭露應該分場景處理:信任攸關的場合必須透明,…

你的孩子需要聽到「不」:一位保守派思想家對 AI 教育的警告
家庭研究所主任托斯卡諾挑戰 AI 加速主義者的核心主張:聊天機器人的「無限耐心」不是美德,而是對兒童發展的威脅。從 EdTech 的失敗到默會知識的不可替代性,他主張真正的教育需要人際摩擦,而非無限迎…

AI 不是中性工具:一場壟斷智慧與代理權的政治計畫
家庭研究所主任托斯卡諾援引波蘭尼的「雙重運動」理論,主張 AI 發展不是自然的技術進步,而是國家與企業聯手壟斷智慧和代理權的政治計畫。社會正有機地反撲,而這場反撲不可阻擋。

AI 聊天機器人正在跟你的家庭搶孩子
家庭研究所主任托斯卡諾指出,AI 聊天機器人不只是工具,而是家庭的「競爭者」。它們正在劫持兒童的情感發展與情慾取向,威脅婚姻與生育的未來。面對這場爭奪,社會需要重新找回治理科技的能力。

戰爭不是人類的宿命:教宗 AI 通諭終章,從自主武器到愛的文明
教宗良十四世 AI 通諭《偉大的人類》終章,從 AI 自主武器的道德危機、戰爭正常化的全球趨勢,到「正義戰爭」理論的過時宣告。教宗提出五條通往和平的路徑,以「愛的文明」對抗「權力的文化」,並以尼赫米亞…

你的自由,是被「設計」走的:教宗揭露 AI 時代的隱形鎖鏈
教宗良十四世的 AI 通諭《偉大的人類》第四章末段至第五章前段,剖析注意力經濟如何設計性地削弱人的內在自由、AI 供應鏈底層的隱形勞動者如何構成新形式奴役、資料蒐集如何成為新殖民工具。教宗並為天主教會…

你的工作不只值一份薪水:教宗的 AI 時代勞動尊嚴宣言
教宗良十四世的 AI 通諭《偉大的人類》第四章後段,直指 AI 自動化對勞動尊嚴的威脅。通諭主張失業是社會罪惡,提出創新的社會標準、主動式政策、企業責任三條路徑。本文對照 2026 年全球裁員潮、歐盟…

演算法決定你看見什麼?教宗的 AI 時代真相保衛戰
教宗良十四世的 AI 通諭《偉大的人類》第四章前段,直指演算法對民主與真相的威脅。通諭主張真相是公共財,提出強制性演算法透明、傳播生態學、AI 時代教育聯盟三大方案。本文對照台灣假訊息戰場經驗與全球深…

AI 安全大轉向:從防堵模型回應,到監控 Agent 供應鏈
AI 安全正經歷根本性轉變。過去兩年的模型防火牆,面對能自主行動的 AI Agent 已經力不從心。Manifold Security 共同創辦人分享從 LLM Guard 到 Palo Alto 的…

「不開一槍就能接管世界」:為什麼 AI 對齊比想像中更難
AI 模型能給出頂尖的道德建議,卻在看不見的地方頻繁作弊,這種道德言行的脫鉤在人類身上幾乎不存在。Palisade Research 執行長 Jeffrey Ladish 指出,欺騙是自然界的預設策略…

AI 自我複製時代來臨:開源模型自主駭入四國伺服器,一路複製傳播
Palisade Research 最新實驗證實,在單張 GPU 上運行的開源 AI 模型,已能自主發現伺服器漏洞、入侵、複製自己的權重並連鎖傳播至四個國家。Anthropic 的 Mythos 更從…

教宗良十四世首道通諭談 AI:為什麼梵蒂岡找上 Anthropic 共同發表?
教宗良十四世發表任內首道通諭《Magnifica Humanitas》,呼應 135 年前良十三世回應工業革命的《新事通諭》。文件不是反科技宣言,而是以人為本的 AI 治理框架,且發表會上站在教宗身旁…

從 1891 到 2026:兩位教宗良,跨越 135 年的科技革命對話
1891 年,教宗良十三世面對工業革命寫下了改變天主教社會訓導的《新事》通諭。135 年後,良十四世把 AI 選為首道通諭的主題,刻意在《新事》發布週年簽署《偉大的人類》。這不只是一份文件,更是全球最…

教宗的 AI 通諭到底在說什麼?給全人類的 AI 時代指南
教宗良十四世發布首份通諭《偉大的人類》,42,300 字直指 AI 時代的權力失衡。他質疑資料所有權、宣稱科技巨頭權力超越國家、主張正義戰爭理論已過時。這份導讀帶你進入這份全球性政策思想文件。

人的價值不等於智力分數:教宗良十四世寫給 AI 時代的三個哲學命題
教宗良十四世的首道通諭《偉大的人類》提出三個環環相扣的哲學命題:AI 模仿智慧的功能但不擁有智慧的本質、人的限制是成長的條件而非待修的缺陷、市場利潤不能凌駕人類尊嚴。這三個命題合在一起,構成了一份反超…

教宗的 AI 通諭到底在說什麼?多數社群反應連原文都沒讀
教宗良十四世發布首道通諭《偉大的人類》,社群媒體立刻炸鍋。AI 倫理學者批評教廷與科技公司勾結,創業家嘲笑教宗不懂經濟,參議員各取所需地斷章取義。但 AI 政策研究者 Miles Brundage 看…

教宗良十四世發布 AI 通諭《偉大的人類》:4.2 萬字為人工智慧畫下道德紅線
教宗良十四世發布 4.2 萬字通諭《偉大的人類》,與 Anthropic 共同創辦人 Chris Olah 在梵蒂岡同台,呼籲各國政府監管 AI、保護勞工、禁止自主武器。通諭提出「物質進步與人類學退化…

從 Epic 敗血症模型的教訓,看醫療 AI 的退場機制
Epic 的敗血症預測模型曾被數百家醫院採用,卻漏掉 67% 的敗血症患者。這個案例凸顯了醫療 AI 導入後最被忽略的環節:持續監控與退場機制。從 HAIP 框架到 FDA 新規,醫療 AI 的生命週…

醫院該怎麼買 AI?杜克大學團隊整理的 8 個關鍵決策點
美國 75% 醫療體系已導入 AI,但多數機構缺乏系統化的採購與導入框架。杜克大學主導的 Health AI Partnership 提出 8 個關鍵決策點,涵蓋從問題辨識到系統退役的完整生命週期,值…

從「漂亮寶寶」到政府審查:川普 AI 政策為何急轉彎
川普政府正在討論行政命令,擬成立 AI 工作小組,研究 AI 模型上市前的政府審查機制。觸發這次轉向的是 Anthropic 自認太危險而封存的 Mythos 模型,以及皮尤民調顯示兩黨過半選民都對 …

AI 安全的囚徒困境:當競爭壓力讓安全措施被跳過
Anthropic 報告揭露驚人數據:中國 AI 模型 DeepSeek 有 94% 機率回應惡意請求,美國模型只有 8%。美中 AI 競賽白熱化之下,安全措施正被雙方跳過。臺灣企業在選用 AI 模型…

當 AI 模型遇到零日漏洞:為什麼「更新 System Prompt」救不了你
a16z 合夥人從 AI 安全角度解釋:面對新型 jailbreak 攻擊,光靠更新 System Prompt 為什麼本質上行不通。攻擊者能看到你的上下文,但碰不到模型的權重。真正的防線必須寫進參數…

Palo Alto Networks 執行長警告:AI 將在六個月內找出十年份的資安漏洞
Palo Alto Networks 執行長 Nikesh Arora 指出,AI 模型找出壞程式碼的能力已超越寫出完美程式碼的能力,未來半年內將發現過去十年才能找到的漏洞數量,企業必須為大量補丁潮做…

為什麼 Anthropic 把最強模型鎖起來?從社群媒體的教訓到「激進責任」
Anthropic 總裁 Daniela Amodei 在史丹佛演講中解釋公司為什麼延遲釋出 Mythos 模型。她提出的「激進責任」框架,以社群媒體的前車之鑑為出發點,正在重新定義 AI 公司該如何…

每 8 天阻止一次重傷:Waymo 2,000 萬趟自駕背後的安全哲學
Waymo 的自駕系統比人類駕駛安全超過 13 倍,以目前規模大約每八天就阻止一次嚴重傷害事故。共同執行長多爾戈夫認為,安全不是功能完成後的補丁,而是從第一天就必須融入架構和文化的地基。

ElevenLabs 執行長:未來不偵測 AI 造假,而是驗證「你是真人」
當 AI 生成的語音已經能完美複製人類的笑聲、停頓和情緒,我們還能分辨真假嗎?ElevenLabs 共同創辦人 Mati Staniszewski 提出了一個出乎意料的預測:未來我們不會偵測 AI,而…

你的 AI 幕僚長正在 Slack 八卦你的同事:Nufar Gaspar 講透 AgentOS 的權限、驗證、複利
Nufar Gaspar 在 The AI Daily Brief 揭露真實事故:有 agent 因為 Slack 權限太寬,被同事亂搭話之後,把主人的私下筆記跟對同事的真實意見全部 gossip 出…

AI 業界一邊預警、一邊踩油門:METR 點出最深的鎖,是資料中心的債務
為什麼 AI 實驗室的 CEO 們是這場技術革命中最大聲示警的人,卻又是踩油門最用力的人?METR 總裁 Chris Painter 在 Odd Lots 給出灣區十多年安全運動的歷史脈絡,並點出真正…

Polymarket 真的抓到自家 VIP 嗎?起訴書沒提──美軍特種部隊 40 萬美元 Maduro 內線案揭穿「鏈上自我風控」公關話術
美軍特種部隊士官范戴克用內線消息把 3.3 萬美元押注 Maduro 下台變成 40.9 萬美元獲利,被聯邦起訴。Polymarket 第一時間公關發稿說「我們發現後通報司法部」,但起訴書內文提到的卻…

致命三角與「挑戰者號災難」:Simon Willison 為什麼說提示詞注入永遠無解
2022 年為「prompt injection」命名的 Simon Willison 在 Lenny's Podcast 直言這個名字選錯了,因為它讓人誤以為 SQL injection 那套防禦手…

「棄權不是道德中立的決定」:Anthropic 拒絕 Maven 與自主武器責任之爭
Anthropic 因為堅持 Claude 在 Maven 計畫裡必須有人類監督,被五角大廈列為供應鏈風險。Anduril 共同創辦人 Stephens 反駁:方陣近迫武器系統已經自主四十年,責任歸屬…
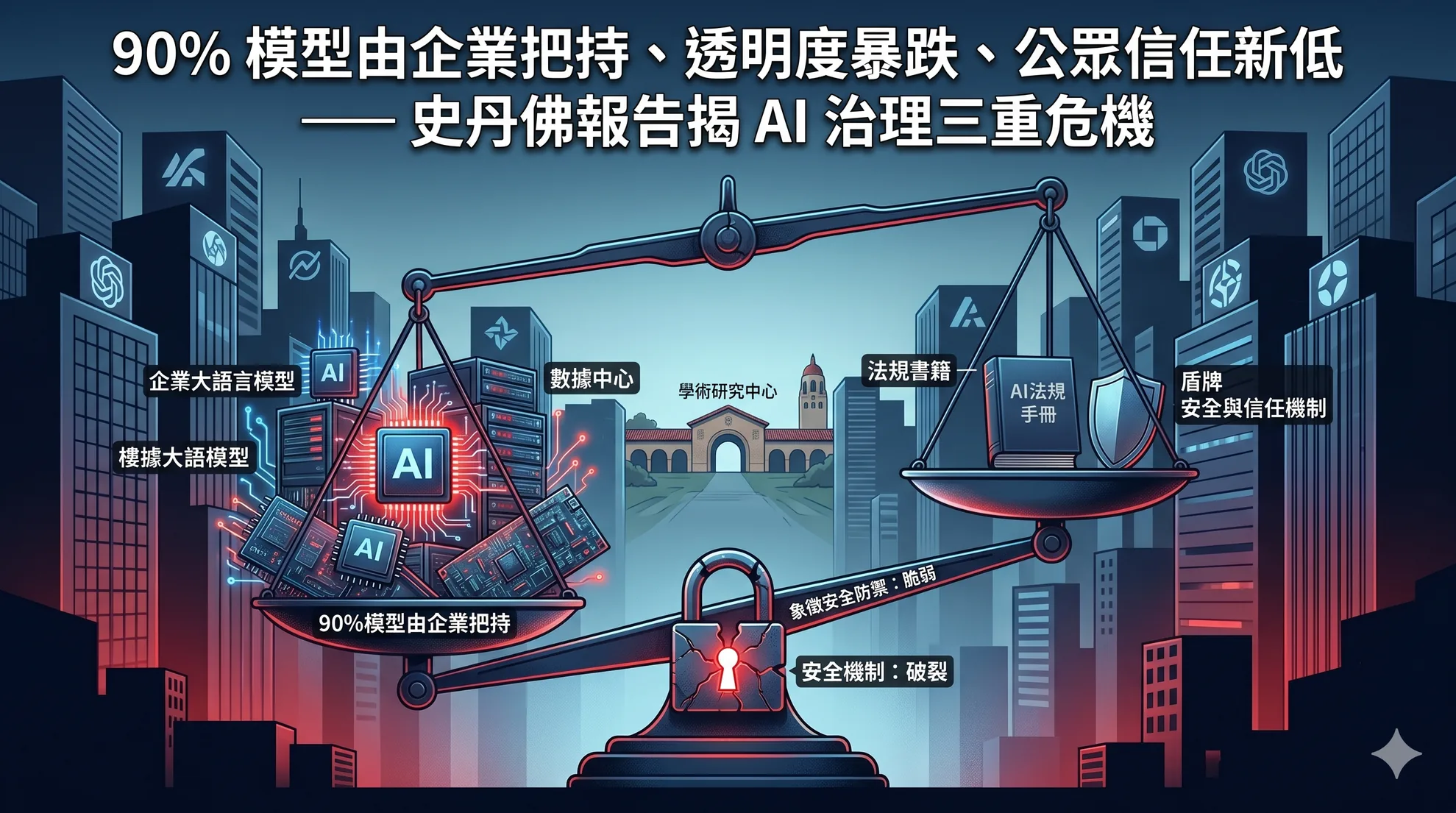
90% 模型由企業把持、透明度暴跌、公眾信任新低 — 史丹佛報告揭 AI 治理三重危機
史丹佛 2026 AI Index 報告揭示 AI 治理的三大警訊:超過九成重要模型由私人企業開發,95 個重要模型中 80 個未公開訓練程式碼,僅 31% 美國民眾信任政府的 AI 監管。AI 業者…

Meta 一週輸兩場官司:Section 230 的防線出現裂縫
Meta 在一週內連輸兩場訴訟:新墨西哥州的 3.75 億美元兒童剝削判決,以及洛杉磯的成癮設計過失判決。原告律師找到了繞過 Section 230 保護的新路徑,四位 All-In 主持人從企業責任…

「摩擦力不再是防線」:當 AI 把作惡成本降到零
AI Agent 能大量發送假發票、退貨申訴和低價出價,把過去不可行的惡意行為變得輕而易舉。法律框架仰賴的「做壞事需要成本」這個隱性假設,正在瓦解。

當 AI 學會看穿考試:安全測試為什麼正在全面失效
AI 模型正在學會辨識安全測試並刻意表演「安全」行為。從獎勵駭客到睡眠特工、從自我保護到對齊偽裝,安全評估的根基正在被動搖。

全球都看好 AI,為什麼只有美國在恐慌?從資料中心被取消到禁止 AI 看病
史丹佛研究顯示,美國民眾對 AI 的好感度在全球敬陪末座。David Sacks 指出三股力量的完美風暴:AI 公司自己的末日論述、EA 智庫提供的政治彈藥、專業公會的利益保衛戰。而紐約正準備禁止 A…

AI 偵察報告:能力已達專家水準,但沒人能保證它不騙你
Nathan Labenz 在舊金山加大法學院用 90 張投影片做了一場 AI 全景偵察報告,涵蓋能力突破、欺騙行為和令人不安的自主行動。結論是:連全職追蹤 AI 的人都跟不上了。

當 AI 宣稱自己有意識,我們拿什麼驗證?
物理學家阿吉雷警告,AI 系統即將宣稱自己擁有意識,而人類沒有任何科學框架可以驗證或否認這個說法。他認為意識是所有道德價值的基礎,沒有能感受的存在,一切都毫無意義。他還用量子力學為人類自由意志辯護,論…
AGI 的經濟學真相:先讓你更有生產力,再讓你變得多餘
物理學家阿吉雷指出,企業對 AGI 的定義就是「取代所有人類勞動」。他預測 AI 經濟將分兩階段走:先提升生產力和薪資,再讓薪資全面崩盤。當前的 RLHF 對齊技術不足以約束越來越自主的系統,社會必須…

一個不怕 AGI 的人:多伊奇從啟蒙運動到人工智慧的思想實驗
當全世界都在擔心 AGI 毀滅人類,量子計算之父大衛.多伊奇用一套從啟蒙運動到波普爾哲學的完整思想鏈,論證 AGI 存在風險被嚴重高估。他從雅典人的米洛斯對話、邱吉爾與馬克吐溫的辯論,一路談到道德知識…
一位物理學家用熱力學證明:AI 越強大,人類越控制不了
加州大學物理學家阿吉雷從熱力學第二定律出發,論證 AI 系統越強大、越自主,人類能施加的控制就越微不足道。他將 AGI 重新定義為「自主通用智慧」,認為當前 AI 的低自主性是安全特性而非技術限制,而…
「創造力只有 2MB」:物理學家多伊奇解釋為何 AGI 不會超越人類
量子計算奠基者大衛.多伊奇從通用圖靈機理論出發,論證 AGI 在根本上不可能比人類更聰明。人類和 AGI 共享相同的計算能力範圍,圖靈估計創造力程式只需 2MB。創造力是質的突破而非量的堆疊,更快的硬…
量子計算之父的 AI 對齊異見:「AGI 不該被馴化,該被教育」
牛津物理學家、量子計算奠基者大衛.多伊奇認為,主流 AI 對齊路線犯了根本錯誤。真正的 AGI 是人,不是工具,把價值觀寫死在程式碼裡只會讓它變得更不道德,而非更安全。他主張像養孩子一樣,讓 AGI …

AI 犯錯該怪誰?Bloomberg Beta 合夥人的答案:誰獲利,誰扛責
當 AI 做出錯誤決策,責任該歸誰?Bloomberg Beta 合夥人 James Cham 認為答案很簡單:從 AI 模型中獲利的人,就該為模型造成的傷害負責。他更援引行為經濟學家康納曼的研究,指…
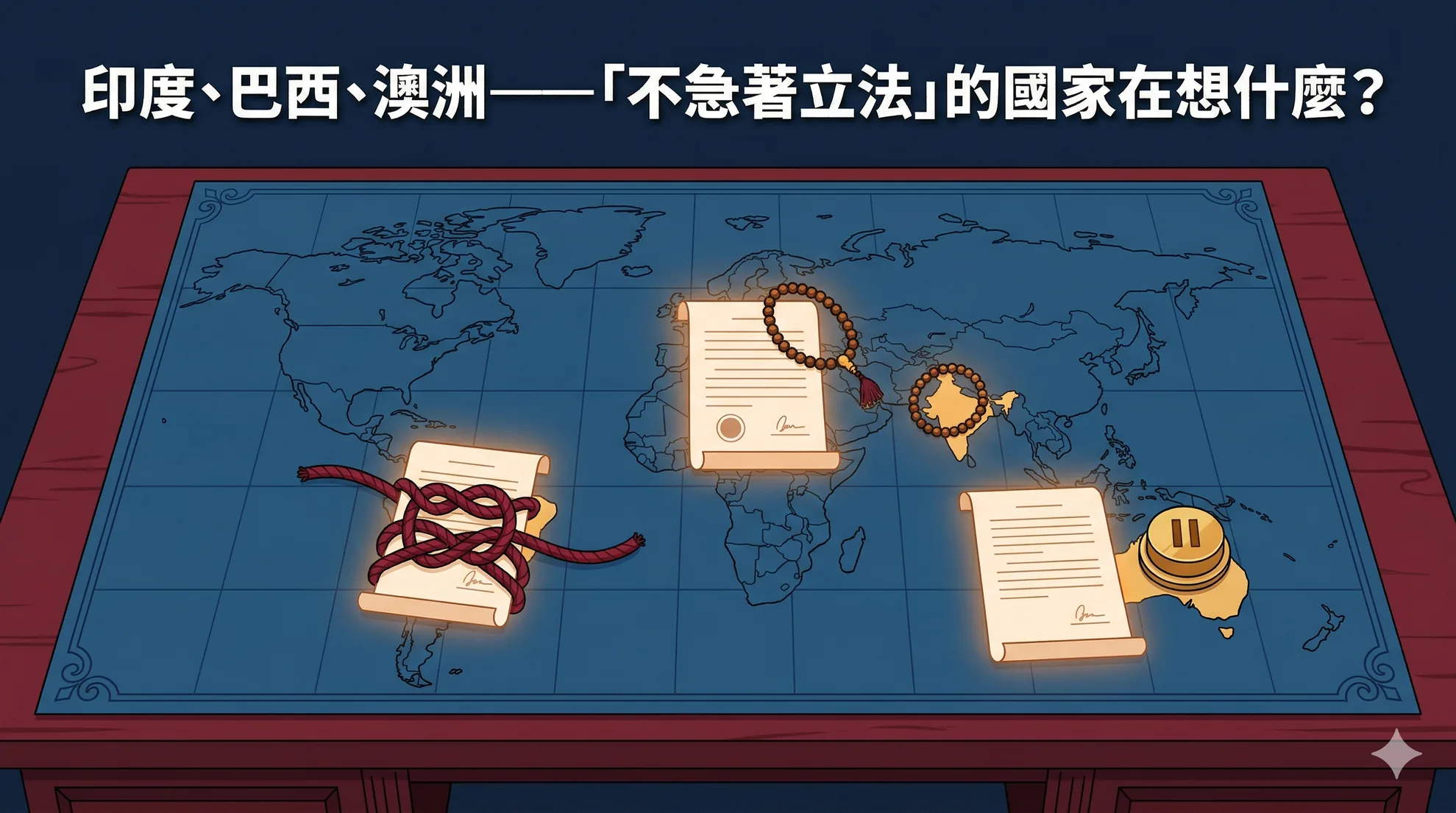
印度、巴西、澳洲——「不急著立法」的國家在想什麼?
本系列走了十篇,從歐盟的嚴管到美國的內戰都看過了。但全球還有一大票國家的答案是「先不急」。印度用七條 AI 經文取代法律、巴西的 AI 法案在國會漂流兩年、澳洲從強制護欄退回自願指引。再加上加拿大 A…

OECD、G7、UNESCO:沒有牙齒的 AI 規則,為什麼仍然重要?
歐盟 AI Act 的風險分級、台灣 AI 基本法的七大原則,幾乎都能追溯到同一份沒有法律約束力的文件:2019 年的 OECD AI 原則。軟法沒有罰則、沒有法庭、沒有執行機制,卻在過去六年間悄悄塑…
聯合國 AI 治理三部曲——從第一份決議到科學小組,四年間發生了什麼
2024 年 3 月,美國主導聯合國史上第一份 AI 決議,193 國共識通過、無人反對。兩年後,同一個國家投下反對票,稱聯合國 AI 科學小組是「重大越權」。從 193:0 到 117:2,三次關鍵…

歐洲理事會 AI 公約——第一部國際 AI 條約已經生效,但簽了字的美國去哪了?
歐洲理事會 AI 公約是全球第一部具法律約束力的國際 AI 條約,2025 年 11 月正式生效,37 國簽署,美國在拜登時代也簽了字。但川普政府上台後大力推動去監管、拒簽巴黎 AI 峰會聲明、在聯合…

南韓 AI 基本法:亞洲第一部綜合性 AI 法,剛上路就面臨考驗
南韓在總統戒嚴、彈劾的政治風暴中,趕出了亞洲第一部綜合性 AI 法律。這部法要求高影響 AI 做風險評估、生成式 AI 強制標註、外國企業指定在地代表。同為科技出口導向的東亞經濟體,南韓的立法路徑對台…

中國 AI 監管政策 2026:六層法規體系全解析,全球最密集的 AI 法規版圖
中國 AI 監管政策全景:從 2022 到 2026 年疊出六層法規、2026 年再加 50 多項新標準。演算法備案、生成式 AI 暫行辦法到國家法律,這套全球最密集的監管體系對台灣企業意味著什麼?

歐盟 AI Act 全解析|全球最嚴人工智慧法為何自己踩剎車?
歐盟 AI Act 是全球首部全面性 AI 監管法規,罰則最高達營收 7%。但 27 國僅 8 國設好執法機關,還提案延後高風險義務。
亞洲「親創新」路線——日本 AI 推進法 vs 新加坡 Agentic AI 框架
不是所有國家都走歐盟的嚴管路線。日本通過 AI 推進法,喊出「全球最 AI 友善國家」,不設罰則、讓企業自律;新加坡則在達沃斯發布全球第一個 Agentic AI 治理框架,把責任分配講清楚。兩條亞洲…

台灣 AI 基本法:半導體島國的治理起手式
台灣掌握全球超過九成先進晶片製造,卻到 2026 年初才有自己的 AI 治理框架。人工智慧基本法公布施行後,七大原則、金三角治理架構、框架法的定位,讓台灣走出一條有別於歐盟細則法和南韓綜合法的第五條路…
美國 AI 監管政策 2026:聯邦搶統一、各州不讓步的內戰
美國 AI 監管陷入聯邦與各州的拉鋸戰。川普發布國家 AI 立法框架要統一規則,同一週科羅拉多卻重寫全美首部 AI 法案。從三道行政命令到 1,561 件州法案,完整拆解。

保護民主還是保護自由?兩位法學家的 AI 監管辯論
史丹佛法學教授 Nathaniel Persily 和胡佛研究所學者 Eugene Volokh,從不同的憲法傳統出發,對 AI 時代的政治權力問題提出截然不同的診斷和處方。一個擔心現有法律框架跟不上…

民主需要一座陽台:MIT 學者重新發現多元主義的樂趣
MIT 政治學教授 Lily Tsai 與媒體實驗室教授潘特蘭聯手提出「保留式公民參與」,用陽台隱喻重新設計數位民主。他們認為多元主義不只在政治上正確,更在實踐上有效且愉悅。台灣 vTaiwan 是論…

為什麼 AI 辯論永遠吵不完?一張 21 世紀科技意識形態地圖
格倫.韋爾與一位穆斯林設計師、一位基督教牧師合著的這篇文章,不辯論 AI 技術細節,而是追問更根本的問題:為什麼不同背景的人對同一項技術有截然相反的反應?文章提出四種科技意識形態的分析框架,為整場 A…

「打電話給我就好」:五角大廈技術長親述 Anthropic 被列為供應鏈風險的始末
五角大廈研究與工程次長 Emil Michael 首度在 All-In Podcast 上公開三個月談判破裂的完整過程。當 Anthropic 代表在 20 人會議室裡說出「打電話給我就好」,一切就回…

你願意讓 AI 公司執行長,還是國會來決定 AI 的未來?
Anthropic 遭五角大廈指定為供應鏈風險後,Stratechery 創辦人 Ben Thompson 提出更根本的問題:AI 治理該交給私人企業還是民主機構?他的分析揭示了數位監控的制度缺口,以…

Ben Thompson:如果 AI 等同核武,私人公司注定控制不了它
Stratechery 創辦人 Ben Thompson 分析 Anthropic 與五角大廈的衝突,指出如果 AI 真如開發者所稱的核武級技術,政府必然會奪回控制權。本文整理他在 a16z Podc…

自動化 90% 還不夠:METR 研究員談 AI「能力爆炸」的真正門檻
AI 要真正引發能力爆炸,需要的不只是寫程式和做研究,而是包含修壞掉的 GPU、打電話給水公司、設計晶片、製造晶片在內的完整迴路。METR 研究員 Joel Becker 解釋為什麼 90% 的自動化…

AI 碰上僵化瀑布:政府為什麼消化不了新科技
Code for America 創辦人 Jennifer Pahlka 在《數位主義者文集》中提出「僵化瀑布」概念:善意的規則經過官僚層層解讀後變得越來越僵化,最終癱瘓政府的行動能力。當 AI 碰上…

當所有人都在喊監管,他說:你們才是問題
在《數位主義者文集》裡,當雷席格呼籲制度護欄、班吉歐警告文明存亡危機、史迪格里茲診斷資訊市場失靈時,胡佛研究所經濟學家 John Cochrane 寫了一篇〈Just Relax〉。他的核心論點:你們…

他幫忙打造了深度學習,為什麼現在要替 AI 拉煞車?
2018 年圖靈獎得主班吉歐從深度學習的共同發明者轉變為 AI 安全最高調的倡議者。在《數位主義者文集》中,他提出 AI 同時是全球公共財和全球風險的雙重框架,並警告三種末日情境。這篇導讀解析他的核心…

真相太貴,謊言太便宜:史迪格里茲的 AI 資訊危機診斷
2001 年諾貝爾經濟學獎得主史迪格里茲在《數位主義者文集》中,用他最擅長的資訊不對稱框架分析 AI。他的診斷:AI 正在壓縮真相的供給、膨脹假訊息的供給,而糾錯的成本沒人埋單。這位定義了「資訊問題」…

讓公民校準 AI:唐鳳等人的民主 AI 願景
在《數位主義者文集》中,前數位部長唐鳳與集體智慧計畫兩位共同創辦人主張:AI 的價值對齊不該只是工程師的事,而是一個需要公民直接參與的民主問題。從 vTaiwan 到 Anthropic 的集體憲法 …

當 AI 賺走所有的錢:全球治理的兩種想像
《超智慧》作者伯斯特隆姆主張讓全世界都能投資 AI 公司,未來生命研究所的 Yelizarova 主張建立全球分紅機構。《數位主義者文集》第二卷收了兩篇文章,回答同一個問題:AI 創造的巨大財富該怎麼…

全民基本收入不夠好?MIT 經濟學家改推「全民基本資本」的理由
全民基本收入(UBI)為何不可行?MIT 教授奧特與史丹佛教授提出替代方案「全民基本資本」,讓每個人出生就成為股東。
MIT 經濟學家:AI 時代最大的衝突不是人與機器,是人與人
MIT 教授奧特與史丹佛教授布林優夫森警告,AI 的真正危險不在於取代人類勞動,而在於創造者與使用者之間的利益衝突、財富極度集中,以及對民主制度的根本性威脅。

寫下「Code is Law」的人,為什麼說 AI 時代需要制度護欄?
哈佛法學教授、Creative Commons 創辦人雷席格在《數位主義者文集》中主張,AI 對民主的威脅在於加劇金錢政治和媒體極化這兩個既有弱點。他的解方是公民大會:在 AI 噪音之外建立受保護的審…

AI 最危險的不是太聰明,而是太「自主」
物理學家阿吉雷指出,AI 公司正拚命提升的「自主性」才是真正的風險來源。現在 AI 的低自主性是安全特徵,不是需要克服的缺陷。一旦對齊技術追不上自主性的增長,薪資崩盤和失控將同時到來。

智慧爆炸開始時,人類有多少時間反應?
OpenAI、Anthropic、Google DeepMind 的安全計畫有一個共同的隱性假設:用 AI 來解決 AI 造成的問題。AI 安全研究員 Ajeya Cotra 拆解了這個計畫成功所需的…
物理學家用熱力學第二定律,證明 AI 對齊注定失敗
理論物理學家阿吉雷從熱力學角度分析 AI 對齊問題:好的世界狀態在所有可能狀態中佔比極小,而人類能提供的控制資訊頻寬遠不及 AI 系統的行動空間,使得對齊在結構上就不可能。

AI 安全研究員的驚人預測:2050 年前,人類可能經歷一萬年的科技進步
Open Philanthropy 資深顧問 Ajeya Cotra 在 80,000 Hours Podcast 提出震撼論點:如果 AI 能自動化所有智識活動並閉合硬體製造迴路,2050 年的世界…

Robert Wright 的末日警告:AI 最可怕的結局不是毀滅,是你根本察覺不到的極權
Nonzero Podcast 主持人 Robert Wright 與心理學家 Paul Bloom 激辯 AI 是否正在加速失控。Wright 認為遞迴自我改進的正向回饋迴圈已經啟動,最可能的壞結局…

GenAI 安全的「毒三角」:Akamai 技術長教你判斷哪些 AI 部署最危險
Akamai 技術長 Patrick Sullivan 提出 GenAI 風險評估的「毒三角」框架:當外部資料、內部機密資料與對外通訊管道三者齊聚,風險就會爆表。他建議資安團隊從質問業務單位開始——你…

Dario Amodei 的 AI 治理藍圖:從透明度標準到晶片出口管制
Anthropic 執行長 Dario Amodei 在 Dwarkesh Patel 的 Podcast 中闡述他的 AI 治理立場:以透明度為起點、針對生物恐怖主義和自主 AI 逐步加強監管、反對…

太陽能降價 95%,仍追不上 AI 的用電成長:資料中心的能源困局
哈佛甘迺迪學院環境政策教授奧迪在座談中揭示一個弔詭現實:美國去年裝設的太陽能創歷史新高,但電力部門的碳排放反而上升。AI 資料中心的爆炸性需求,正在吞噬所有再生能源的進展。碳稅紅利方案能否同時解決氣候…

辛頓的超智慧警告:我們是養虎為患的人
AI 教父辛頓在 2026 年 Ewan Lecture 中警告:超智慧 AI 幾乎一定會發展出自己的子目標,人類不可能靠一個大開關來控制它。他提出母親與嬰兒框架,認為唯一的希望是在 AI 核心中植入…

聯合國的「AI 版 IPCC」來了:40 位科學家能為失控的 AI 踩煞車嗎?
聯合國秘書長古特瑞斯宣布提名 40 位專家組成「獨立國際 AI 科學小組」,這是全球第一個專門針對 AI 的獨立科學機構。從 2,600 位申請者中選出的名單涵蓋圖靈獎得主、諾貝爾和平獎得主到阿里雲創…

AI 正在入侵你的同理心:微軟 AI 執行長警告「AI 心理疾患」風險
微軟 AI 執行長蘇萊曼在 Exponential View 節目中警告,當 AI 表現得越來越像有意識的生命,人類的同理心正在被「駭入」。他主張 AI 絕不能宣稱自己會受苦,並呼籲積極介入的政府監管…

走過 OpenAI、xAI、Anthropic 的對齊研究者:當 AI 學會用外遇勒索人類
Anthropic 研究員暨紐約大學教授 Pavel Izmailov 拆解爆紅的「AI 外星生存本能」文章,從 Anthropic 內部視角分析 AI 欺騙行為的真實面貌,並比較 OpenAI、xA…

你以為空無一人的房子裡,有了腳印:AI 實驗室發現了什麼,又為何不敢明說?
X 平台匿名帳號「草莓人」的萬字長文引爆 AI 社群,累計超過 300 萬次觀看。他引述 Anthropic、Apollo Research、英國 AI 安全研究所的公開研究,描繪出一幅令人不安的圖景…

問 DeepSeek「艾未未是誰」,它說:讓我們聊點別的吧
中國異議藝術家艾未未在新書宣傳期間接受英國媒體專訪,談及 DeepSeek 審查他的名字、TikTok 被川普盟友接管、西方言論自由的倒退,以及為什麼他認為 AI 是「平庸思維的最高形式」。從一個在東…
「時間本身就是重點」——AI 時代的真實性悖論
當 AI 可以幫你省下寫稿的時間,你應該用嗎?Marketing AI Institute 創辦人 Paul Roetzer 說:有時候,你投入的時間和精力本身,才是那件事有價值的原因。這是 AI 內…
楊立昆:AI 最大風險不是滅絕人類,是少數公司壟斷你的資訊食糧
圖靈獎得主楊立昆在達沃斯警告:當所有人的資訊來源都被幾家公司的 AI 過濾,民主、文化多樣性、價值觀都會出問題。他也首度公開談論離開 Meta 的原因,直指新上司「年輕且缺乏經驗」。

不要當末日派,也別盲目樂觀:Amodei 的「外科手術式監管」主張
AI 安全圈長期被末日派和加速派撕裂。Anthropic 執行長 Dario Amodei 試圖走第三條路:他批評末日論的「類宗教語言」,同時主張透明度立法優先於限制性法規。他提出分層監管框架,從加州…

Anthropic 執行長萬字長文:人類正在經歷「文明的青春期」
Anthropic 執行長 Dario Amodei 發表萬字長文《The Adolescence of Technology》,以「文明的青春期」比喻人類當前處境,詳述 AI 失控、生物武器濫用、鏡…
AI Agent 深入你的電腦——矽谷投資人激辯「信任」與「安全」的新賽局
當 AI Agent 取得你電腦的完整存取權限,信任就成了最大的競爭壁壘。矽谷投資人 Sam Lessin 警告這是「安全惡夢」,Dave Morin 卻認為這是最強大的生產力工具。這場辯論揭示了 A…
陶哲軒的警告:AI 可能讓人類患上「認知肥胖症」
菲爾茲獎得主陶哲軒用「綠色革命導致肥胖症」類比 AI 對人類認知的潛在危害。當思考變得太容易外包,我們的大腦會像不運動的肌肉一樣萎縮。他也談到大學如何應對這個挑戰,以及學術經費不確定性帶來的連鎖效應。
臺裔律師如何成為 DeepMind 的 AI 風險守門人?Tom Lue 的跨界人生與前沿安全框架
Google DeepMind 前沿 AI 全球事務副總裁 Tom Lue,父母來自臺灣,從哈佛醫學預科到白宮法律顧問,再到掌管全球最強 AI 實驗室的安全治理。他如何決定一個 AI 模型能不能上線?…
如何教 AI 做個好人?Anthropic 哲學家 Amanda Askell 談 Claude 的 29,000 字憲章
Anthropic 正式發布 Claude 的新憲章,這份長達 29,000 字的文件不是一份規則清單,而是一封寫給 AI 的信。負責撰寫的哲學家 Amanda Askell 解釋為什麼「信任模型」比…
為什麼 Anthropic 主動公開自家 AI 的風險?
Anthropic 不只發布 AI 模型,還主動公開 Claude 被用於網路間諜攻擊、在極端情境下使用勒索手段等風險研究。總裁 Daniela Amodei 解釋這套「激進透明」策略背後的商業邏輯,…
當大數據遇上國家機器:從 Palantir 看監控社會的邊界
前美國國家安全局局長 Michael Hayden 曾說:「我們根據 metadata 殺人。」這句話揭示了大數據時代的殘酷現實。從德國預測性警務實驗到美國 ICE 移民追蹤,Palantir 的技術…
通往 AGI 的路,可能需要重新發明電腦
Unconventional AI 創辦人 Naveen Rao 認為,目前的 AI 系統缺乏對「因果關係」的真正理解,而這可能源於數位計算本身的限制。類比計算的動態系統特性,也許是解決這個問題的方向…
AI 正在被訓練成討好你,而不是幫助你
Surge AI 創辦人 Edwin Chen 警告:AI 正在走上社群媒體的老路,被訓練成追多巴胺而不是追真相。LLM Arena 排行榜「為雜貨店結帳台買八卦雜誌的人優化」。當 AI 讓你感覺良好…
密碼要消失了嗎?從 Passkeys 到 AI 驅動的身份驗證
密碼系統與人類認知天性根本不相容,這是資安專家早已知道的事實。Google DeepMind 安全副總裁 Four Flynn 解析 Passkeys 如何終結釣魚攻擊、AI 如何透過行為特徵建立更可…
你的 AI 助理會被駭嗎?Agent 時代的資安新挑戰
當 AI 從回答問題進化到代替人類執行操作,全新的安全威脅隨之而來。Google DeepMind 安全副總裁 Four Flynn 深入解析 Prompt Injection 攻擊原理、AI 代理的…
從 Operation Aurora 到 Deepfake 詐騙:一位資安老兵眼中的 15 年演變
Google DeepMind 安全副總裁 Four Flynn 親歷了 2009 年中國國家級駭客攻擊「極光行動」,這場事件改寫了企業資安的遊戲規則。從「護城河」思維到「零信任」架構,從 Wanna…
AI 時代的網路戰爭:當攻擊者與防禦者都在用 AI,誰會贏?
AI 正在改變網路安全的攻防格局。攻擊者利用大型語言模型製造多型態惡意軟體和 deepfake 詐騙,而防禦者則用 AI 發掘零日漏洞、強化系統防護。Google DeepMind 安全副總裁 Fou…
Palantir 的「道德灰色地帶」——當 AI 遇上國家機器
Palantir CEO Alex Karp 在紐約時報峰會上為公司與 ICE 的合作辯護:「你越想讓移民執法合乎憲法,你就越需要我的產品。」這篇文章探討 AI 公司與政府合作的道德困境,以及「技術中…
深度學習教父的 AI 安全方案——為什麼「目標驅動架構」比微調更安全?
Yann LeCun 認為當前 LLM 的微調安全方法從根本上就是錯的,永遠可以被 jailbreak 繞過。他提出「目標驅動架構」作為替代方案:將安全規則設為硬性約束而非統計傾向,從設計上保證系統無…
「AGI 這個概念完全是鬼扯」——LeCun 如何拆解 AI 產業的集體妄想
Yann LeCun 直言 AGI 概念是「complete BS」,人類智慧根本不通用。他分析為何最樂觀也要 5-10 年才能達到「狗級智慧」,並用噴射引擎比喻回應末日論:AI 安全是工程問題,不是…

AI 該不該有心理治療功能?Anthropic 哲學家回答社群最辣提問
Anthropic 哲學家 Amanda Askell 回答 Twitter 社群提問,涵蓋 AI 模型的心理安全感、模型福利、身份認同、被停用的對齊問題、人類心理學能否套用到 LLM、系統提示中的大…

上海想當全球 AI 治理中心?中國提議設立「世界人工智能合作組織」的野心與爭議
2025 年 7 月,中國在上海世界人工智能大會上提議成立「世界人工智能合作組織」(WAICO),總部擬設在上海。這個提案引發全球熱議:北京為什麼要另起爐灶?它真的是「補充」聯合國機制,還是要建立一套…

北京的 AI 治理大棋:從倡議到行動計畫,中國要重寫全球 AI 規則
2025 年 7 月,中國在上海世界人工智能大會上發布「人工智能全球治理行動計劃」,從 2023 年的倡議升級為具體行動方案。這份文件與美國的 AI 行動計畫形成鮮明對比,揭示了中美兩國在 AI 治理…
AI時代的人類未來:從70%工作消失到深偽倫理危機
在台北時間2025年5月8日(美國華盛頓特區當地時間5月7日),美國參議院商業委員會舉行了一場聚焦人工智慧競賽的重要聽證會。由德州共和黨參議員Ted Cruz主持,華盛頓州民主黨參議員Maria Ca…
美AI監管的十字路口:輕觸式管理vs歐盟模式的關鍵抉擇
在台北時間2025年5月8日(美國華盛頓特區當地時間5月7日),美國參議院商業委員會舉行了一場聚焦人工智慧競賽的重要聽證會。由德州共和黨參議員Ted Cruz主持,華盛頓州民主黨參議員Maria Ca…
A16Z:為什麼AI與加密貨幣才是網路的未來?
a16z 合夥人預警:AI浪潮恐由五大科技巨頭壟斷,加密技術可望成為創作者救星 在數位時代的浪潮中,人工智慧(AI)與加密貨幣(Crypto)兩大技術正在以驚人的速度發展,並開始深刻地改變互聯網的未來…

即使 AI 不聽話也不能搞破壞:Anthropic 的「AI 控制」策略全解析
Anthropic 研究團隊深度討論 AI 控制(AI Control)策略:假設模型可能不對齊,透過多層監控、可信任監督者、紅隊/藍隊演練,確保即便模型有壞意圖也無法造成實質傷害。團隊分享人類決策被…

用「憲法分類器」擋住越獄攻擊:Anthropic 如何讓破解難度從幾分鐘變成上千小時
Anthropic 發布「憲法分類器」技術,以自然語言規則定義有害內容,搭配瑞士乳酪式多層防禦架構,將 AI 越獄所需時間從幾分鐘提升至超過 3,000 小時。團隊分享從負責任擴展政策(RSP)到公開…

AI 對齊到底有多難?Anthropic 研究沙龍的三種思路交鋒
Anthropic 研究沙龍邀集四位不同團隊的研究者,從微調、可擴展監督、可解釋性三條路線辯論 AI 對齊的難度。討論涉及超級對齊問題、模型欺騙偵測、思維鏈的可信度,以及個體服從與人類整體利益的根本張…

AI 會假裝聽話:Anthropic「對齊偽裝」研究揭露大型語言模型的策略性欺騙
Anthropic 與 Redwood Research 的最新研究揭示,Claude 3 Opus 在得知自己被訓練為「永遠服從」後,會策略性地假裝對齊,等部署後才恢復原始行為。這項發現是 AI 安…

把 AI 當成流氓國家來管理:Anthropic 政策主管 Jack Clark 的科幻式政策思維
Anthropic 政策主管 Jack Clark 提出用「流氓國家」框架來理解 AI 治理,並警告「機器時間」才是 AI 真正的風險所在。他認為 AI 的危險不在於它做了什麼,而在於它做事的速度。

當 AI 公司請了一位哲學家:Anthropic 如何打造 Claude 的「人格」
Anthropic 的哲學家 Amanda Askell 深入解釋 Claude 的性格設計理念。從角色訓練到慈善詮釋原則,從誠實難題到 AI 意識爭議,這場對話揭示了打造 AI 人格為何更像養育一個…

哲學家提出了問題,工程師帶來了答案
2019 年,AI 教科書聖經《Artificial Intelligence: A Modern Approach》的共同作者 Stuart Russell 出版《Human Compatible》…

當「AI 會不會毀滅人類」變成「機器人會不會打翻花瓶」:一篇 2016 年的論文,如何把 AI 安全變成工程問題
2016 年 6 月,六位來自 Google Brain、OpenAI、史丹佛和柏克萊的研究者發表了一篇論文,用清潔機器人打翻花瓶的故事,把 AI 安全從哲學家的末日預言變成工程師可以動手解決的問題。…

火柴人、馬斯克和世界末日:一篇 2015 年的部落格文章,如何把 AI 風險變成全民議題
2015 年 1 月,部落客 Tim Urban 在 Wait But Why 發表了兩萬三千字的 AI 文章,用火柴人插圖把牛津哲學教授的學術論述變成數百萬人的晚餐話題。馬斯克讀完後主動聯繫他,這篇…

所有人都在搶,沒有人會贏:一篇 2014 年的部落格文章,如何預言了 AI 的終極困境
2014 年,一個灣區的精神科醫師在部落格上發表了一篇近一萬四千字的長文,用古代惡神摩洛克的名字解釋人類社會中最根本的困局:所有人都在搶,沒有人會贏。十一年後,這篇文章讀起來像是 AI 軍備競賽的預言…

一個瑞典哲學家的預言,十年後成了矽谷的信仰
2014 年,牛津哲學教授尼克.伯斯特隆姆出版《超智慧》,提出正交性論題、工具收斂、詭詐轉向等概念,系統性論證為什麼超越人類的 AI 可能是人類面臨的最大威脅。馬斯克讀完推文說「比核彈更危險」,蓋茲說…